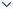数据聚落有效性深度算法图
INTP vs ESFJ
ENTP vs ISFJ
INTJ vs ESFP
ENTJ vs ISFP
ENFJ vs ISTP
INFJ vs ESTP
ENFP vs ISTJ
INFP vs ESTJ
每个类型对比都有三张图片:原始灰度图片,k-means机器学习算法图片,Totypes荣格八维测评网站的算法图片。
我们使用t-SNE算法从高维数据中生成了原始的灰度图片,并对这些图片进行了两种不同的上色处理:一种使用k-means机器学习的算法,另一种使用Totypes荣格八维测评网站的算法。这两种上色方法都在15000名被试的数据上进行了测试。比较结果显示,Totypes荣格八维测评网站的算法在区分度上的表现最为优秀,超过了传统的k-means机器学习算法。这说明Totypes的算法不仅能更准确地识别和区分数据特点,而且在处理类似的复杂数据时更有效。
例如,可以想象我们有一组灰度图像,这些图像通过t-SNE算法生成,每张图像代表一个数据点的多维特征压缩表示。我们用k-means算法和Totypes算法分别对这些图像进行着色。通过对比着色后的图像,我们发现使用Totypes算法的图像中,相似的数据点颜色更统一,不同类别的数据点颜色区分更明显,这表明Totypes算法在维持和展示数据的内在结构方面表现更佳。这种优势可能源自Totypes算法在处理个性化和复杂数据时的高级逻辑和优化策略。
我们所使用的是t-SNE算法,全称为t-distributed Stochastic Neighbor Embedding,中文译为“t分布随机邻近嵌入”。这是一种数据降维技术,主要用于高维数据的可视化。其基本思想是将高维空间中的数据点映射到低维空间(如二维或三维空间),同时尽可能保留数据点之间的局部结构。
举个例子,假设我们有一个包含各种水果的数据集,每种水果都有多种属性(如甜度、颜色、大小等),这些属性构成了一个高维空间。t-SNE算法可以帮助我们将这些高维属性数据映射到二维平面上,使得相似的水果(即属性相近的水果)在平面上也相邻。通过这种映射,我们可以更直观地看到哪些水果是相似的,哪些是不同的。
在t-SNE映射的二维空间中,如果某两类数据点明显分开,则说明这两类数据在高维空间中也有较好的区分度;如果映射后的数据点混在一起,难以区分,则可能是因为原始数据集本身就难以区分,或者这些数据不适合用t-SNE方法降维到低维空间。
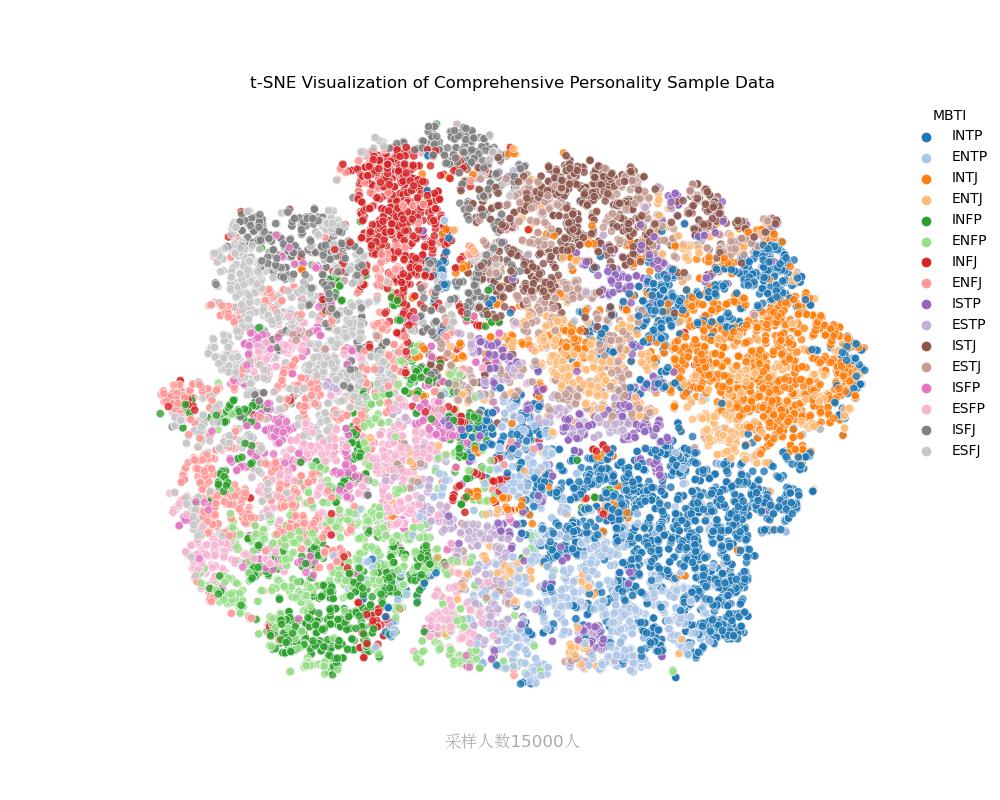
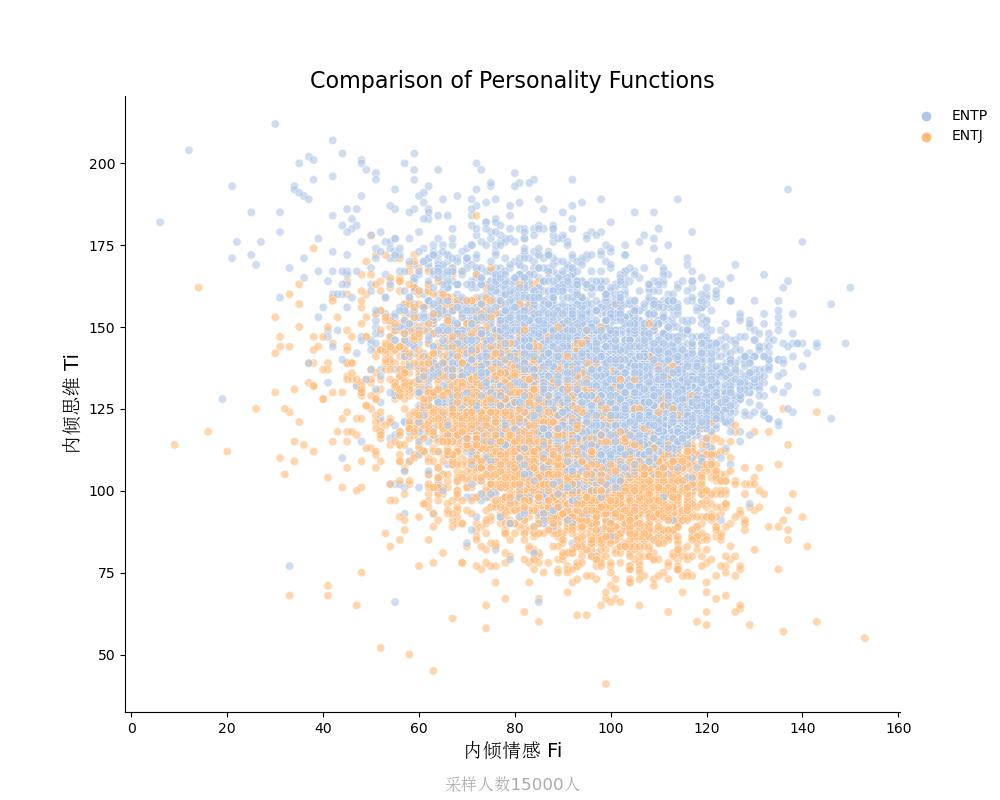
ENTP vs ENTJ
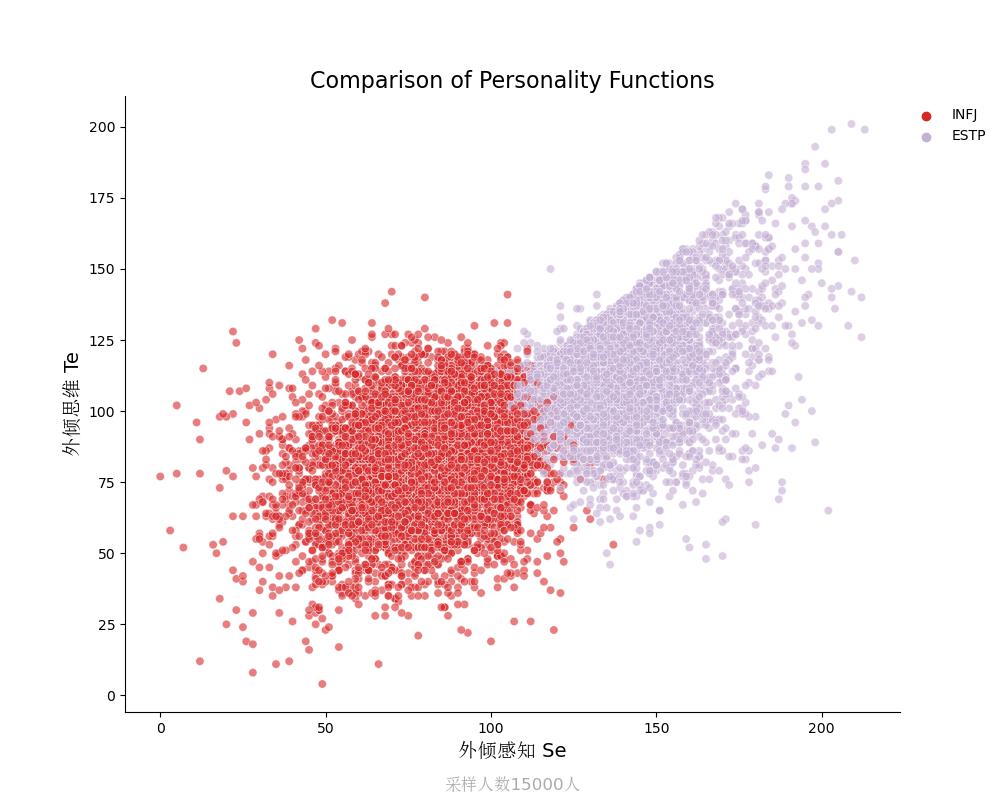
ESTP vs INFJ
多维对比
内倾思维Ti vs 内倾情感Fi
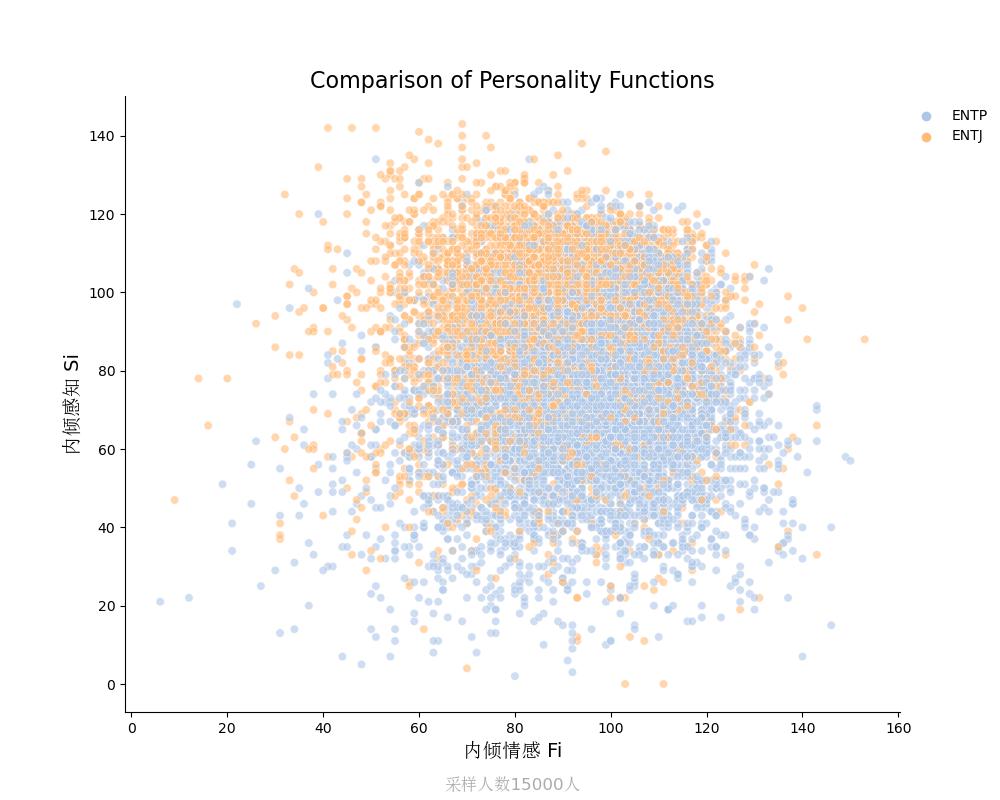
内倾感知Si vs 内倾情感Fi
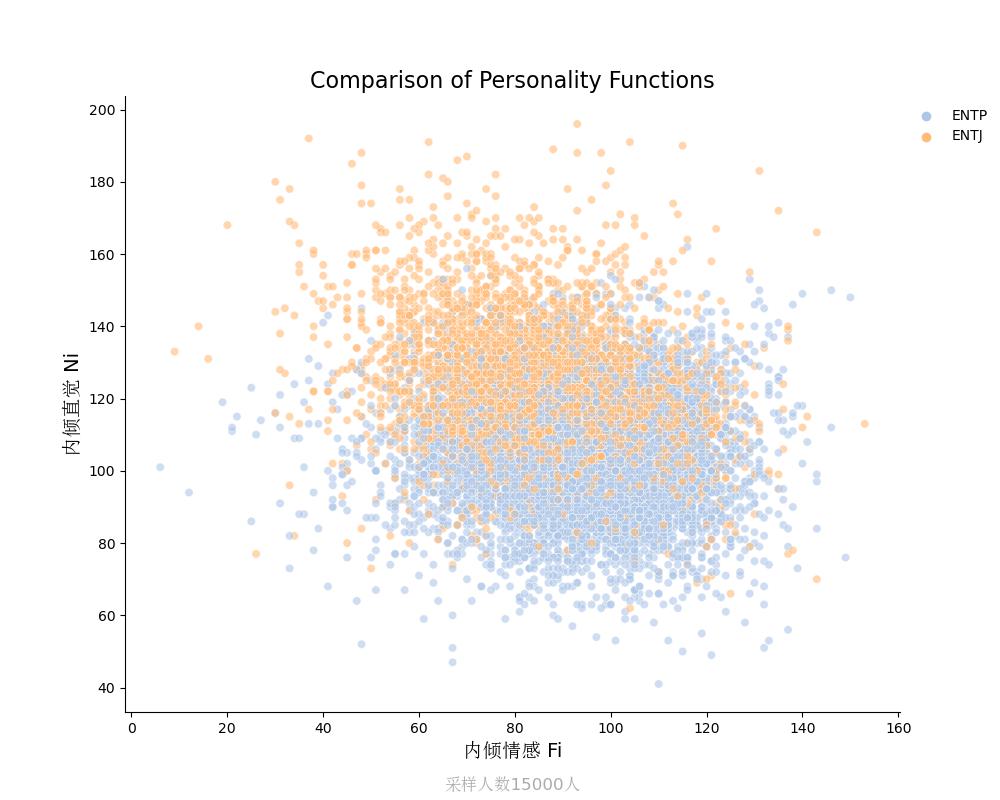
内倾直觉Ni vs 内倾情感Fi
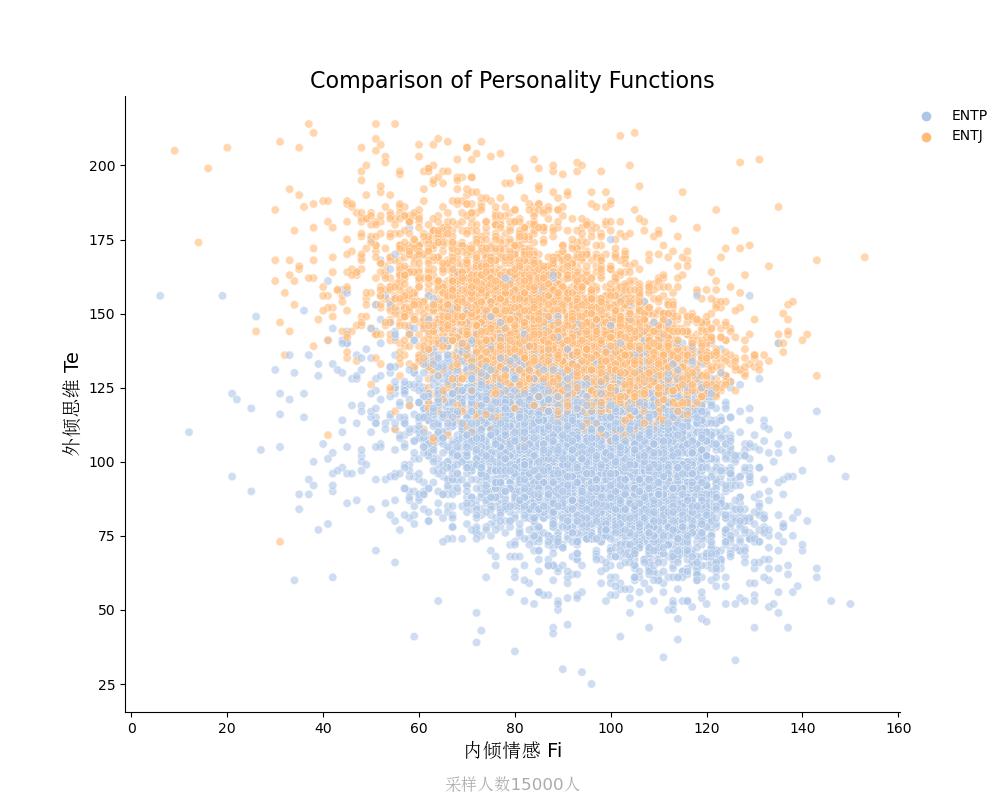
外倾思维Te vs 内倾情感Fi
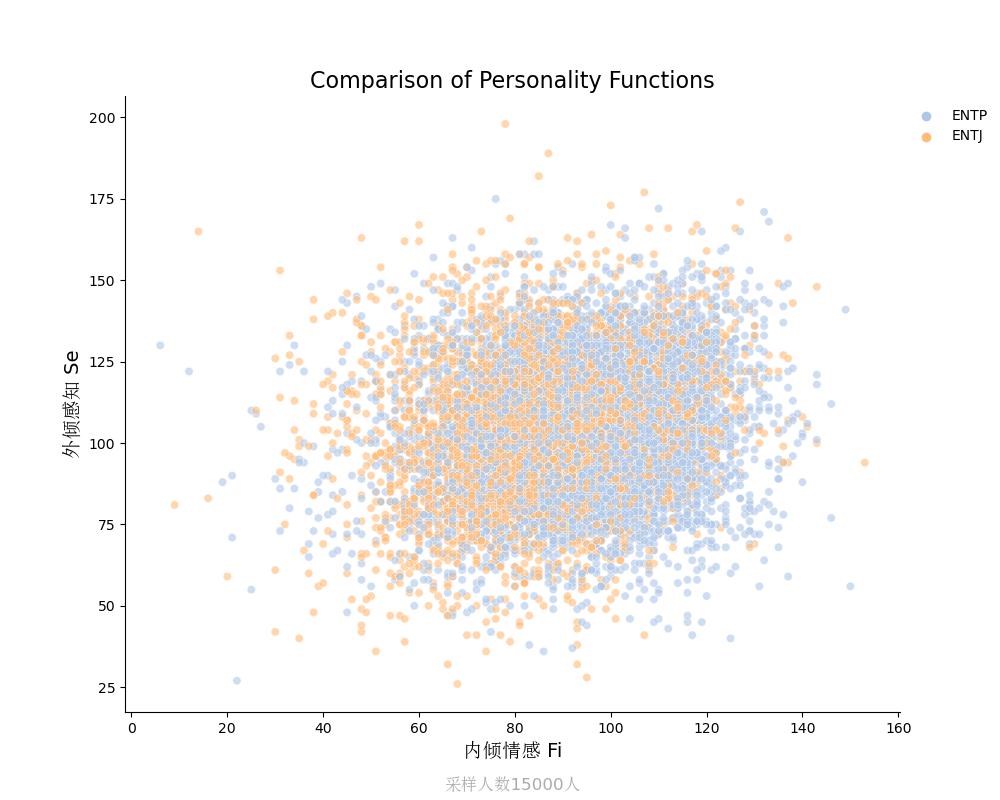
外倾感知Se vs 内倾情感Fi
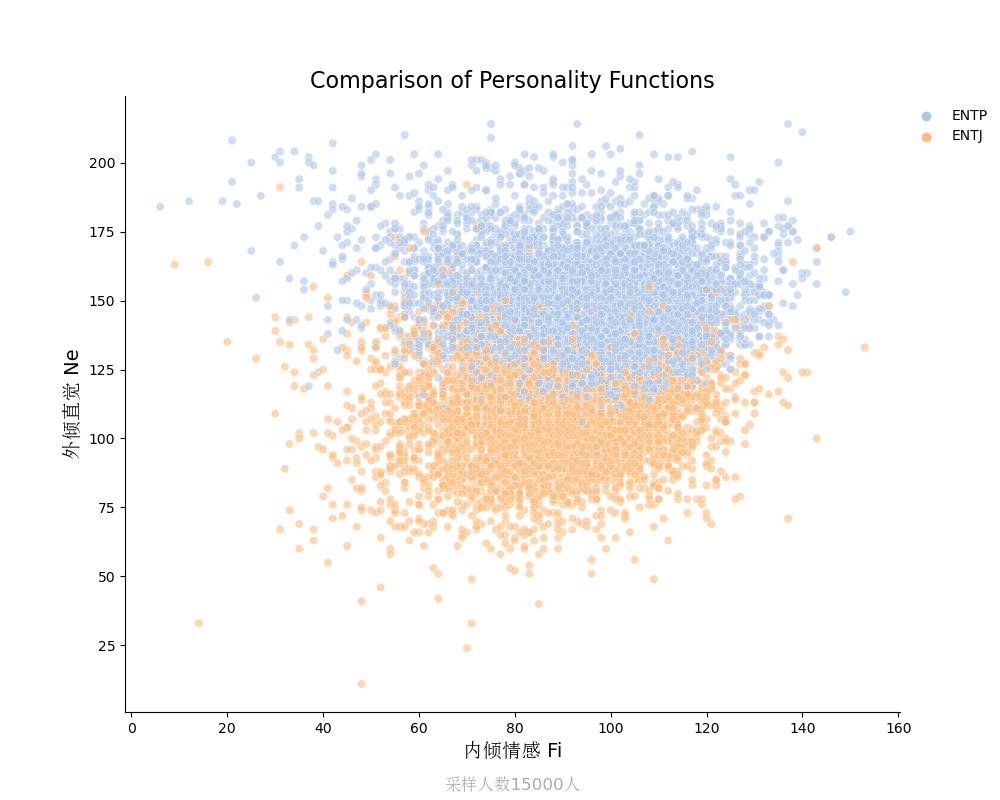
外倾直觉Ne vs 内倾情感Fi
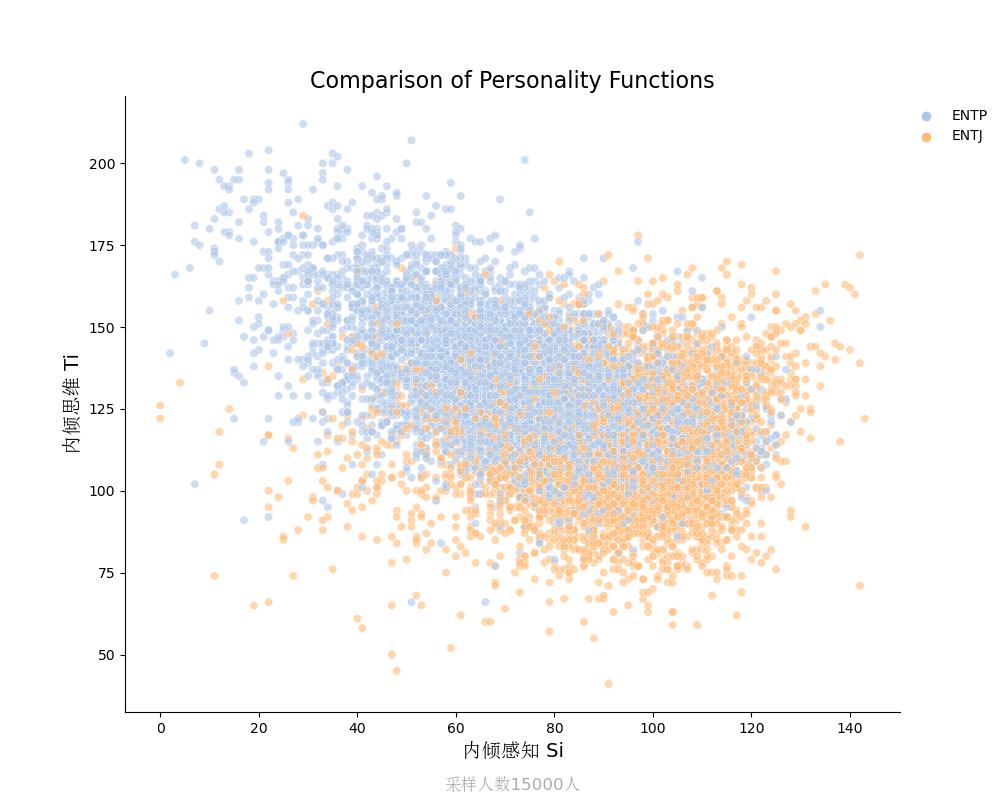
内倾思维Ti vs 内倾感知Si
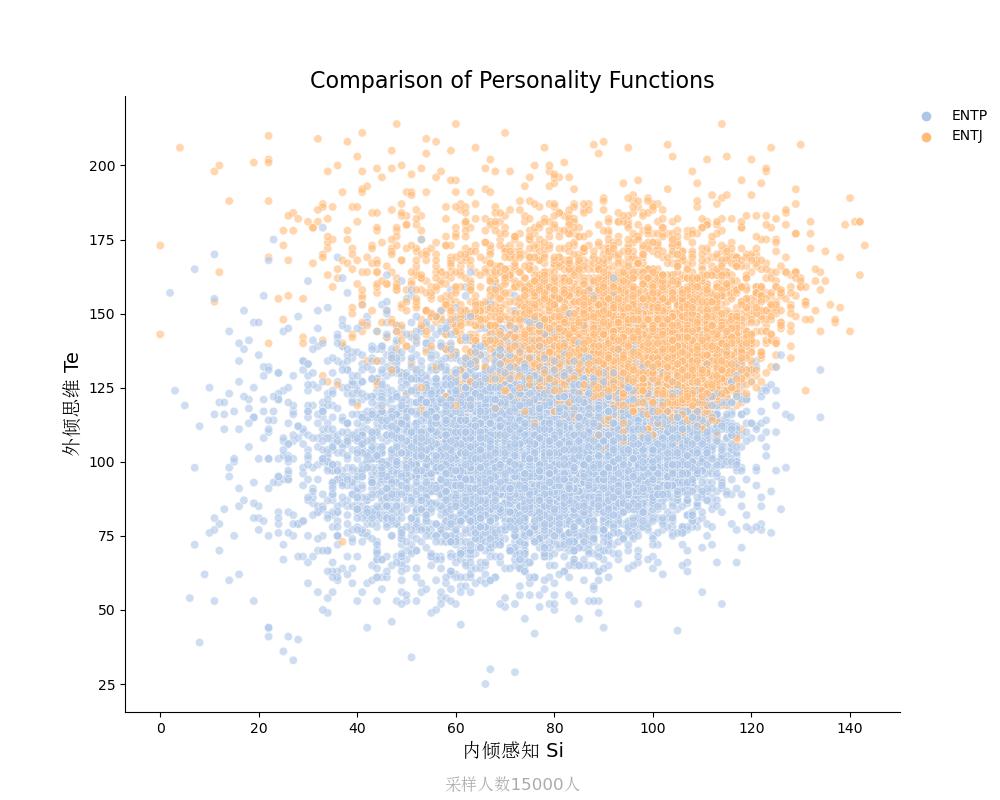
外倾思维Te vs 内倾感知Si
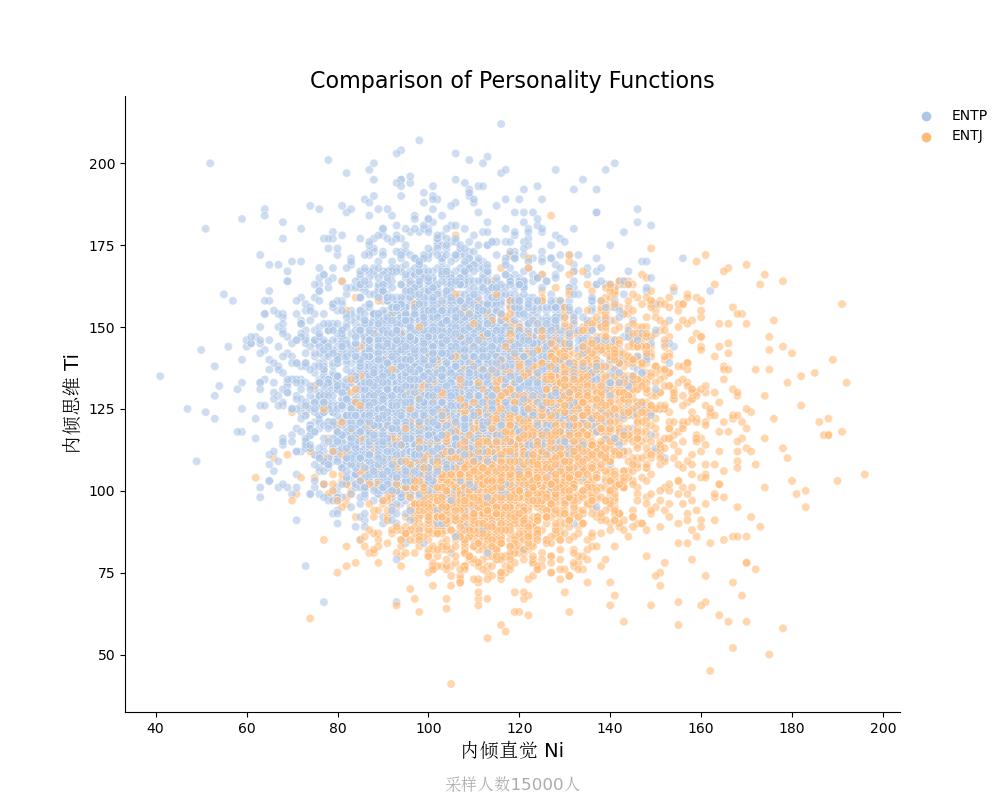
内倾思维Ti vs 内倾直觉Ni
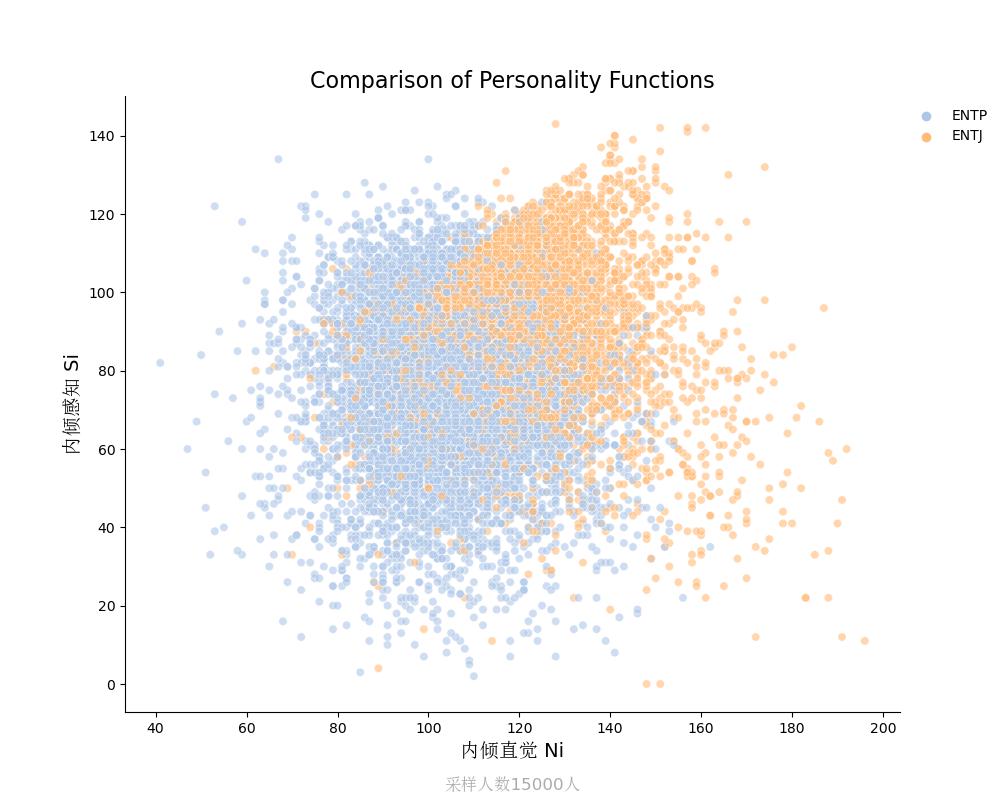
内倾感知Si vs 内倾直觉Ni
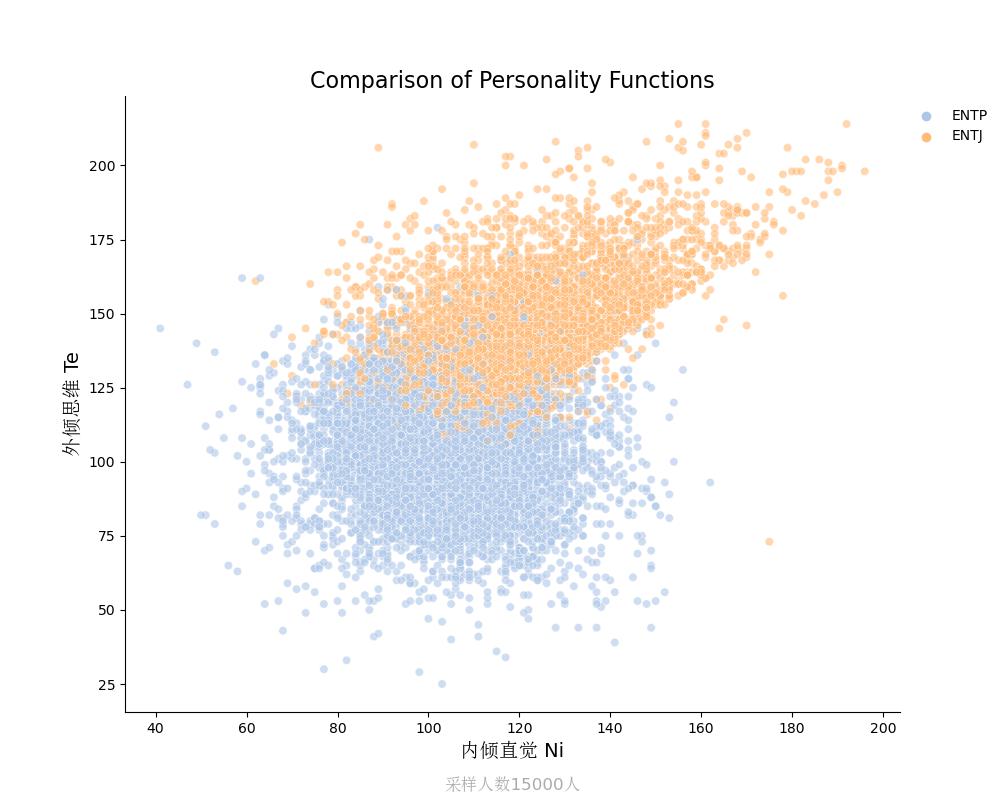
外倾思维Te vs 内倾直觉Ni
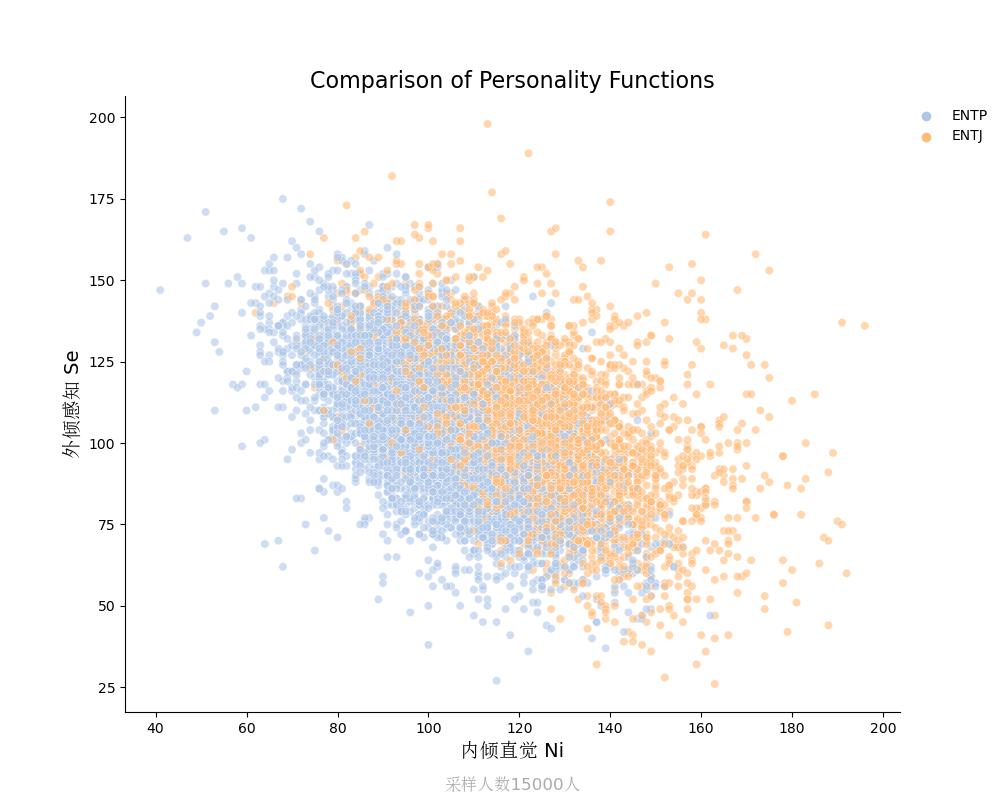
外倾感知Se vs 内倾直觉Ni
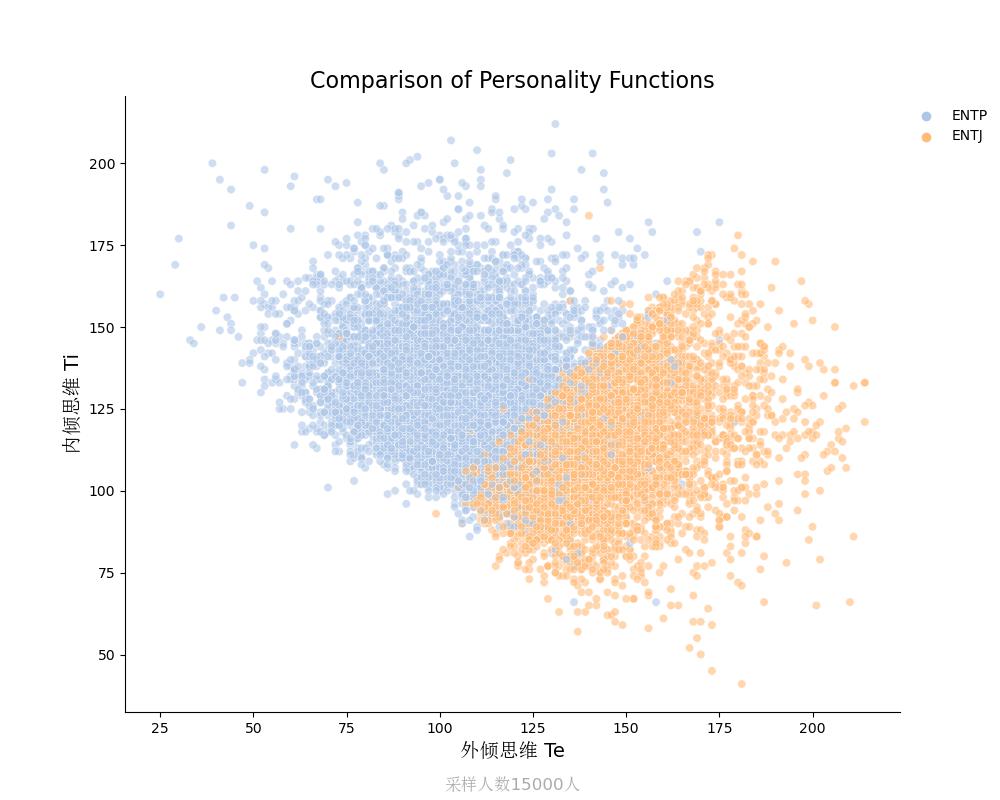
内倾思维Ti vs 外倾思维Te
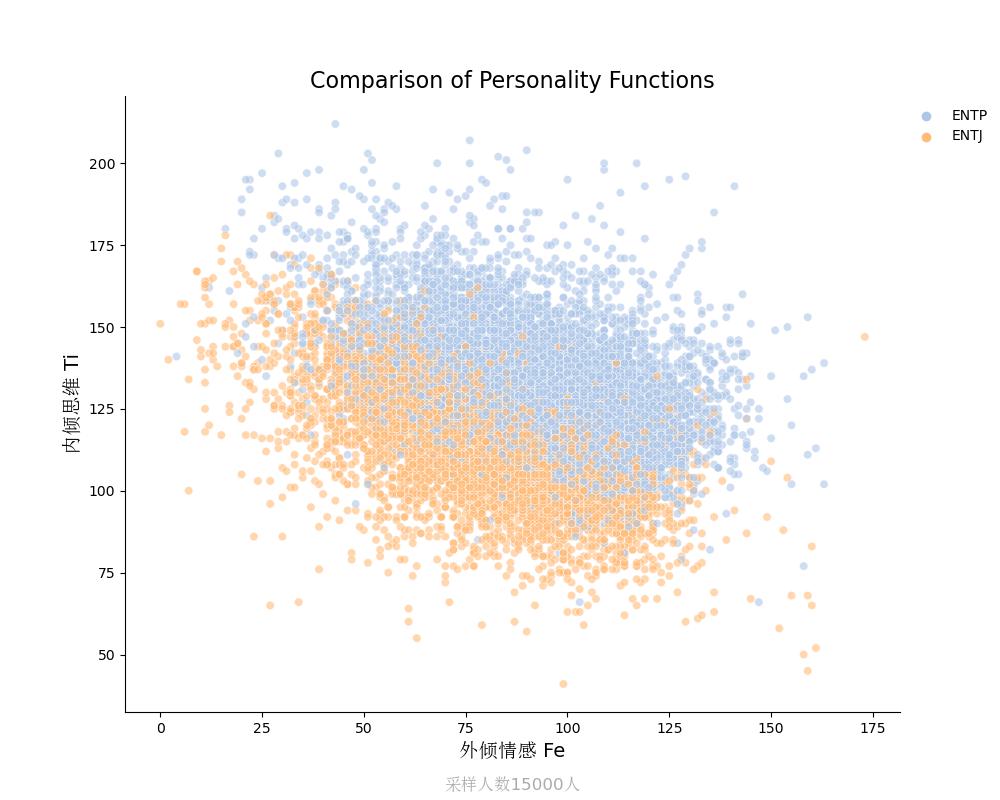
内倾思维Ti vs 外倾情感Fe
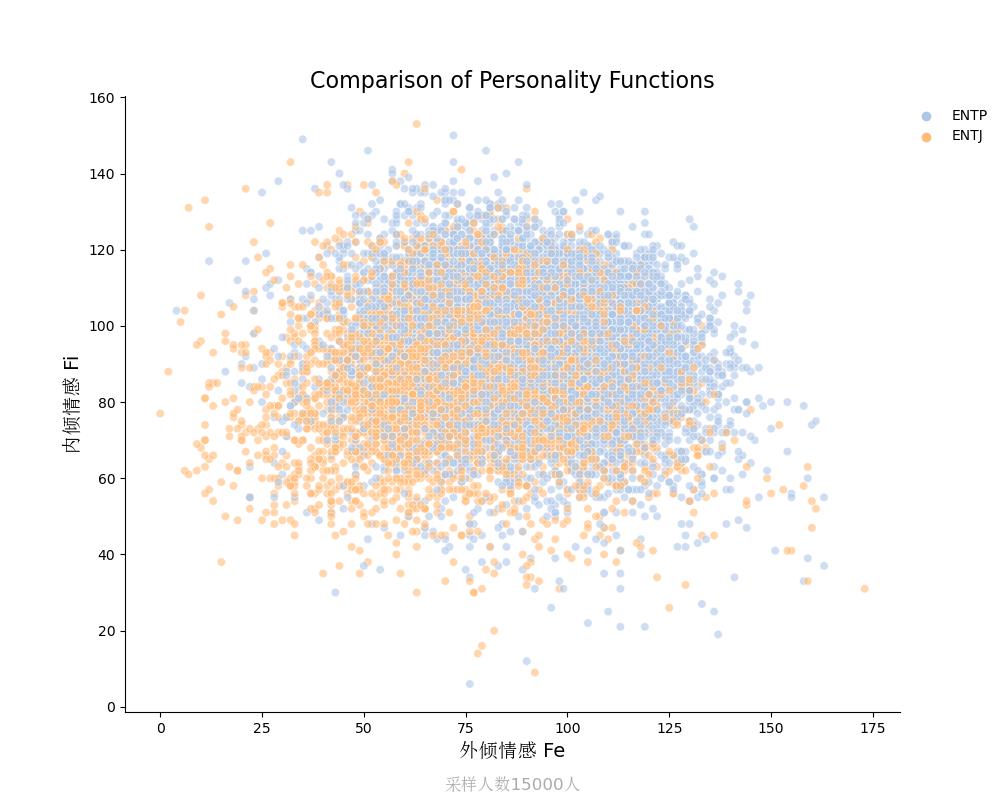
内倾情感Fi vs 外倾情感Fe
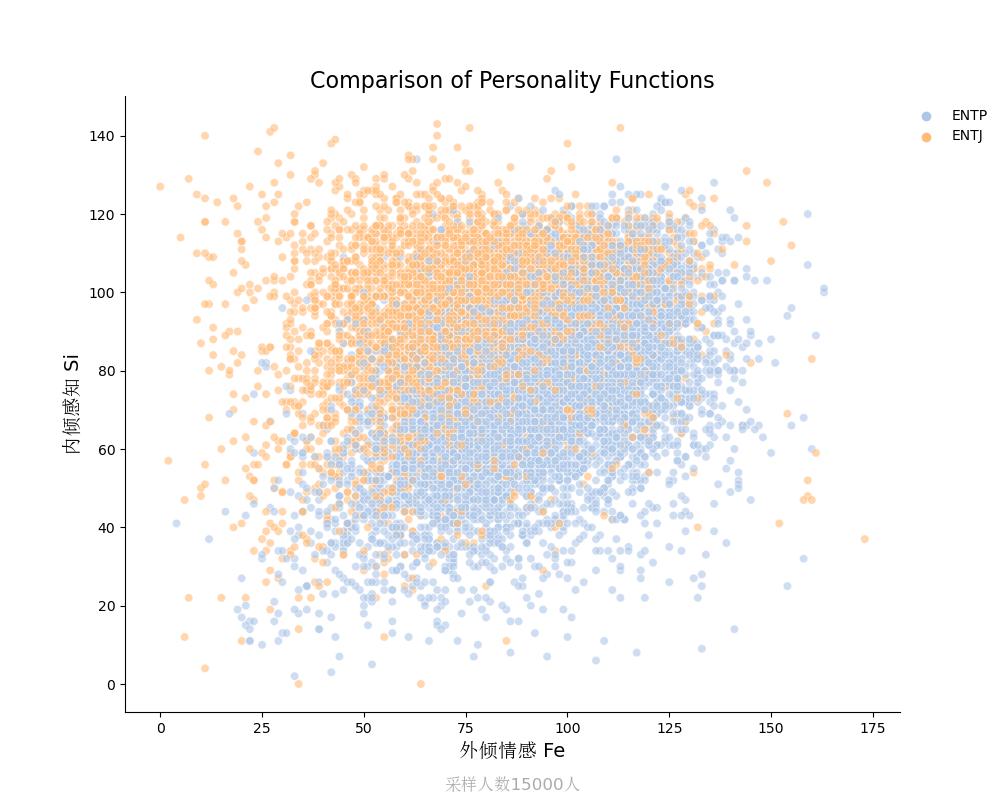
内倾感知Si vs 外倾情感Fe
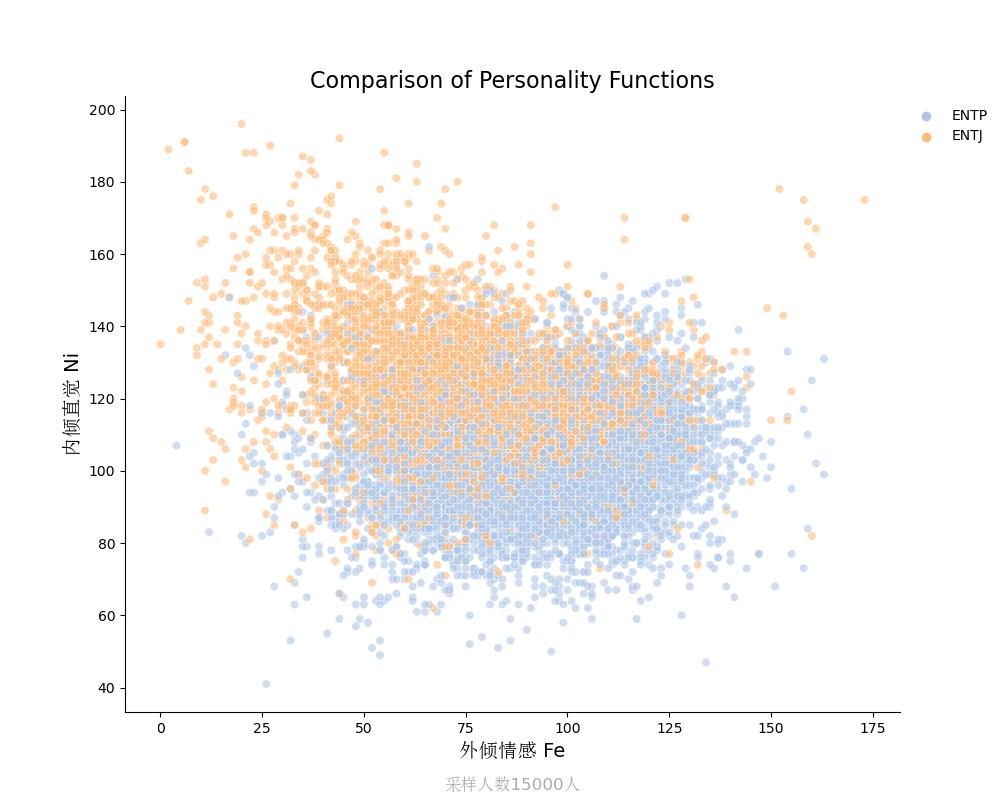
内倾直觉Ni vs 外倾情感Fe
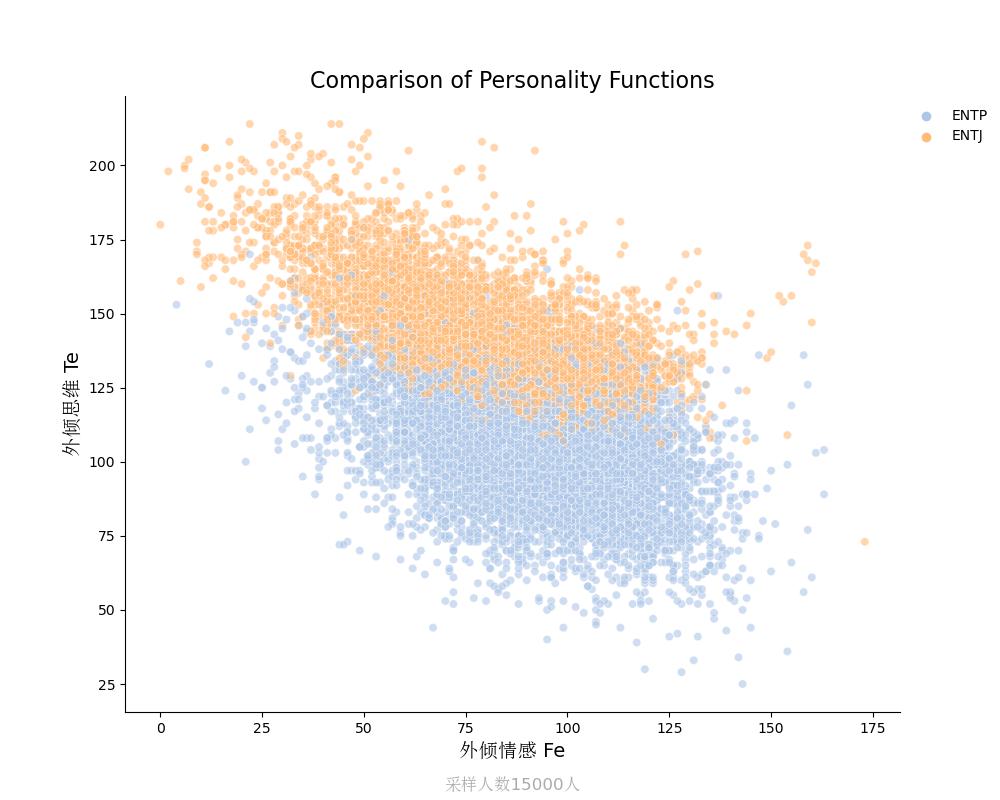
外倾思维Te vs 外倾情感Fe
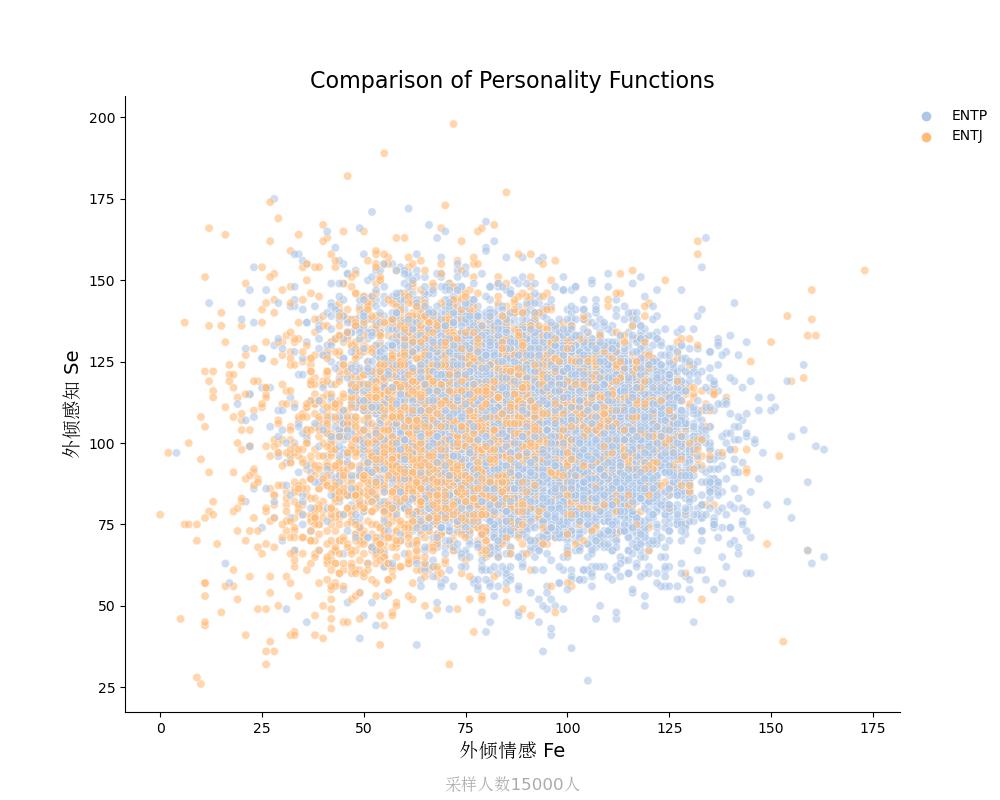
外倾感知Se vs 外倾情感Fe
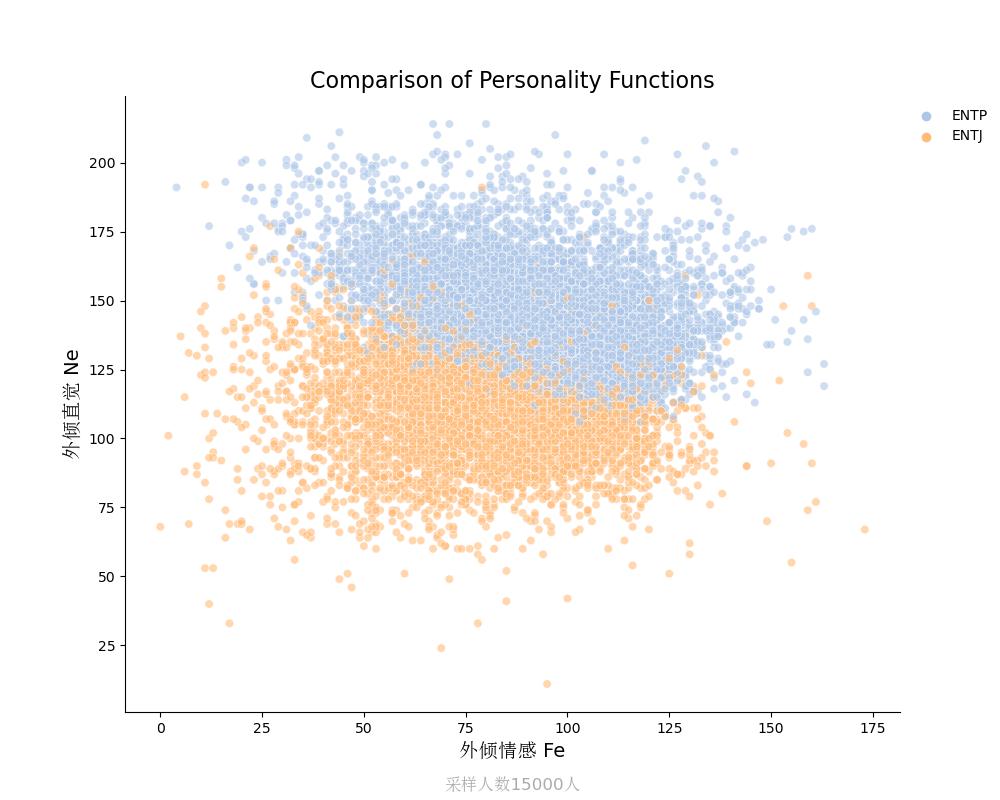
外倾直觉Ne vs 外倾情感Fe
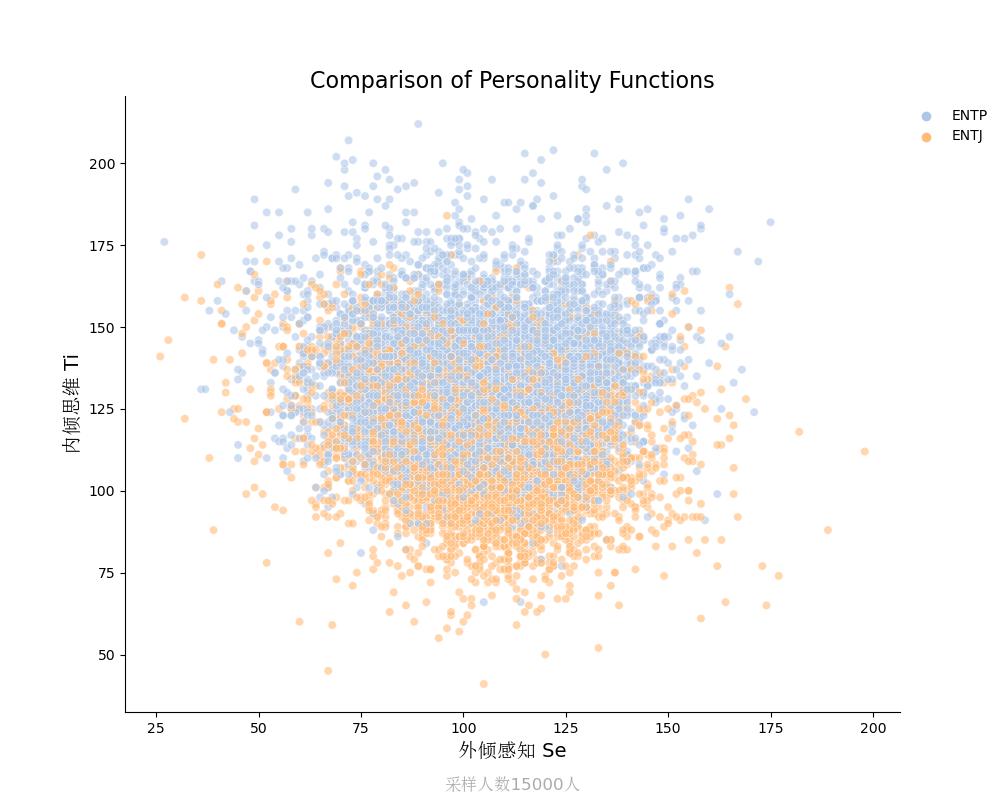
内倾思维Ti vs 外倾感知Se
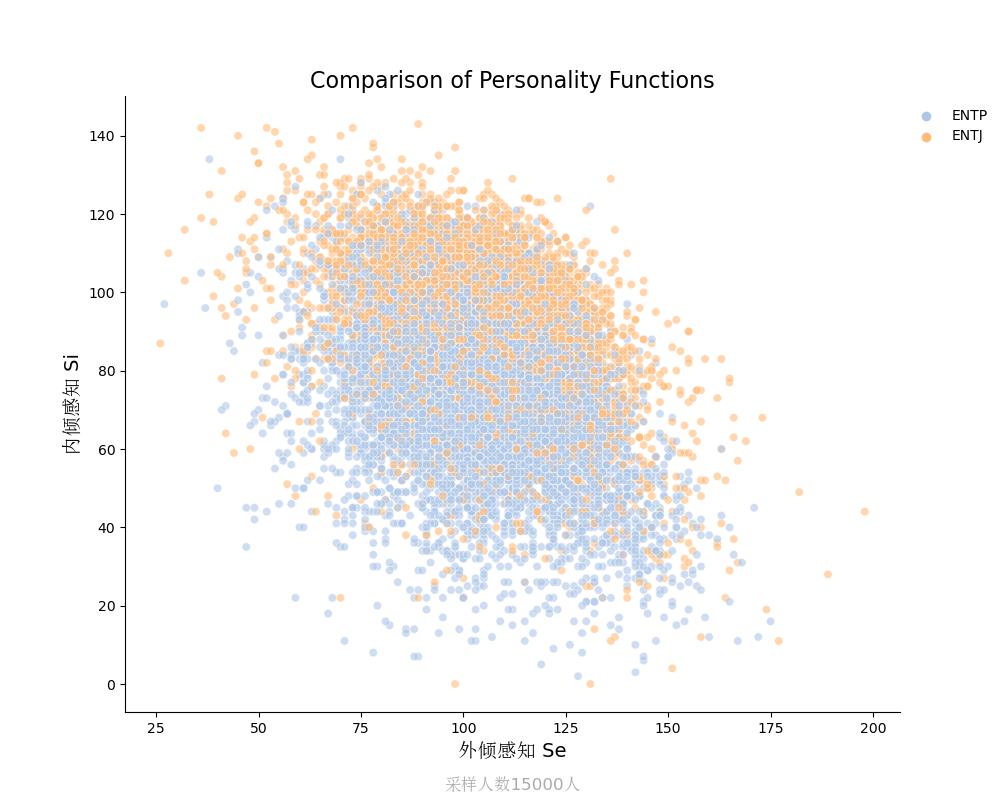
内倾感知Si vs 外倾感知Se
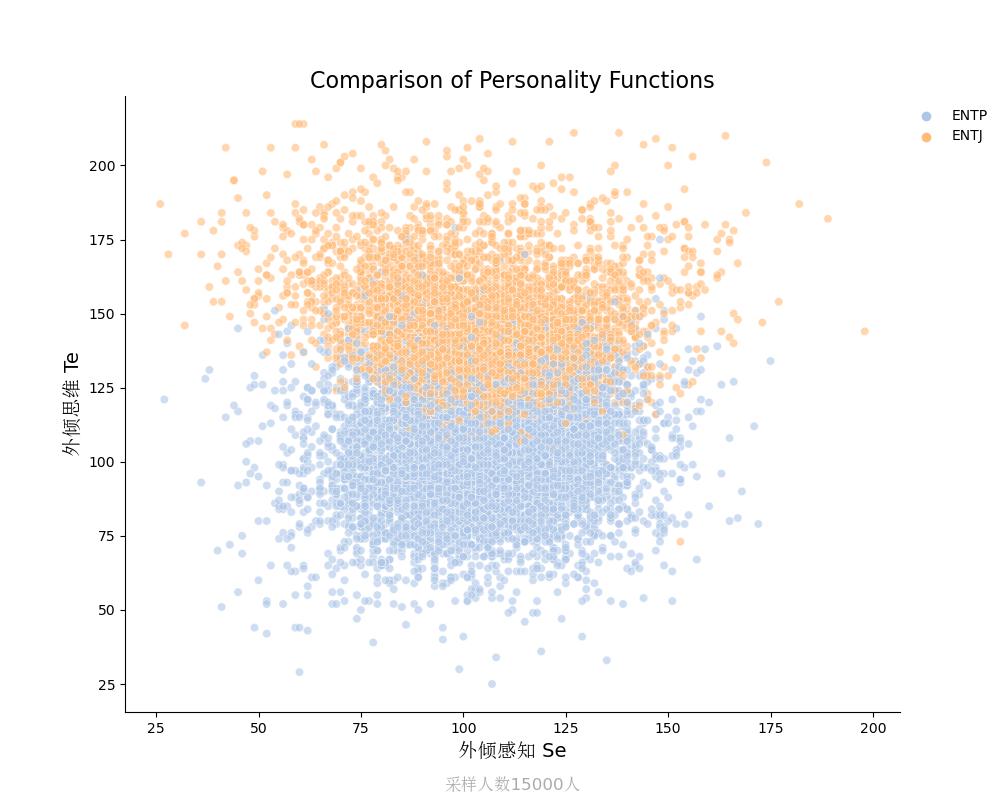
外倾思维Te vs 外倾感知Se
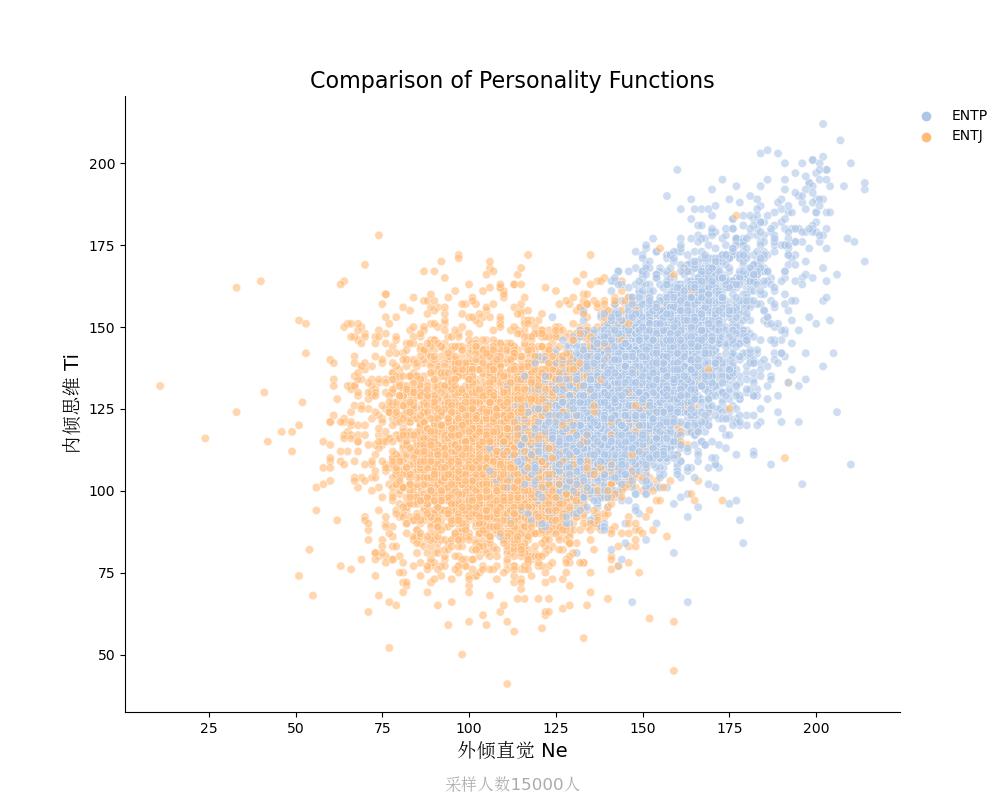
内倾思维Ti vs 外倾直觉Ne
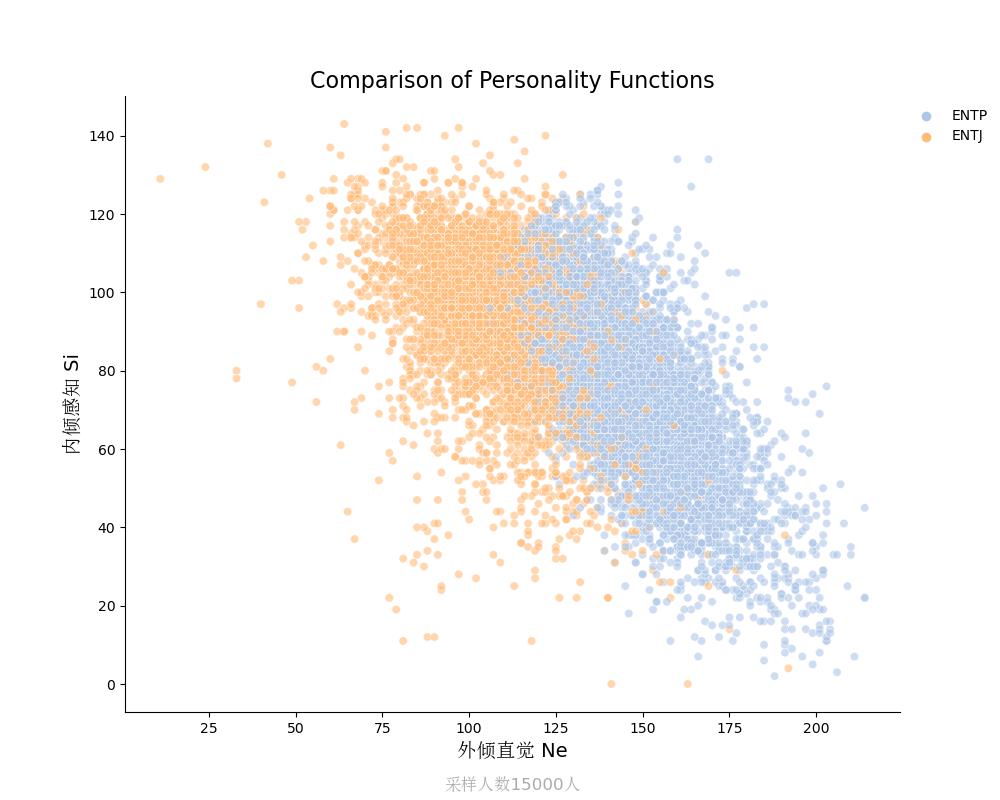
内倾感知Si vs 外倾直觉Ne
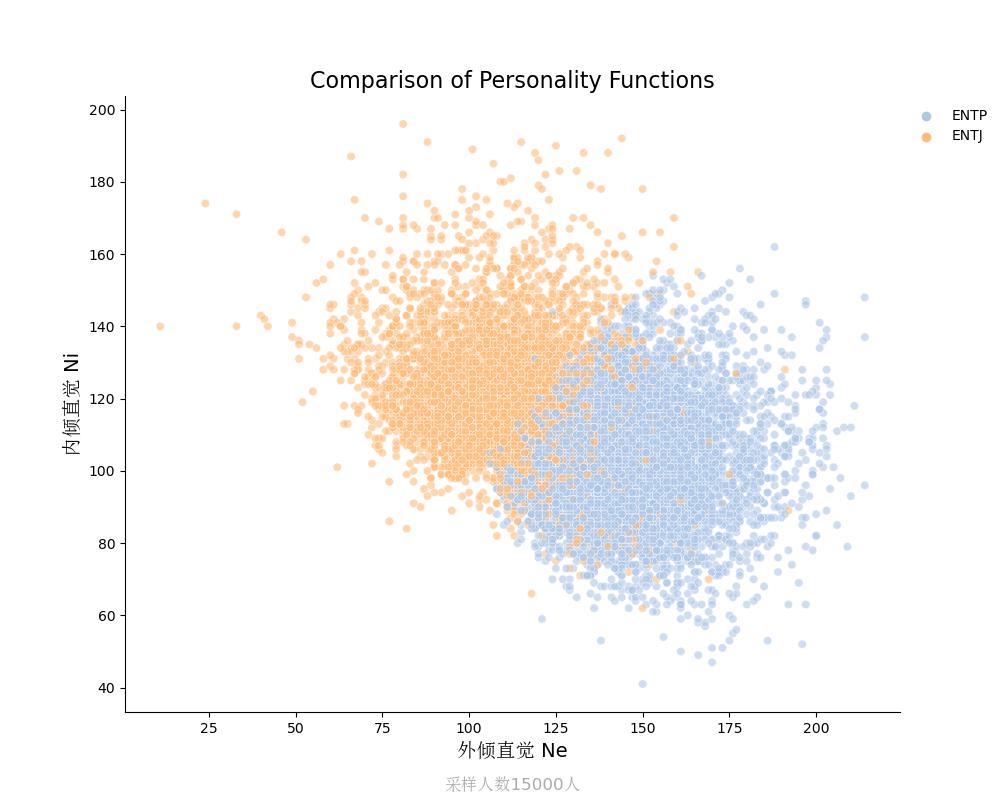
内倾直觉Ni vs 外倾直觉Ne
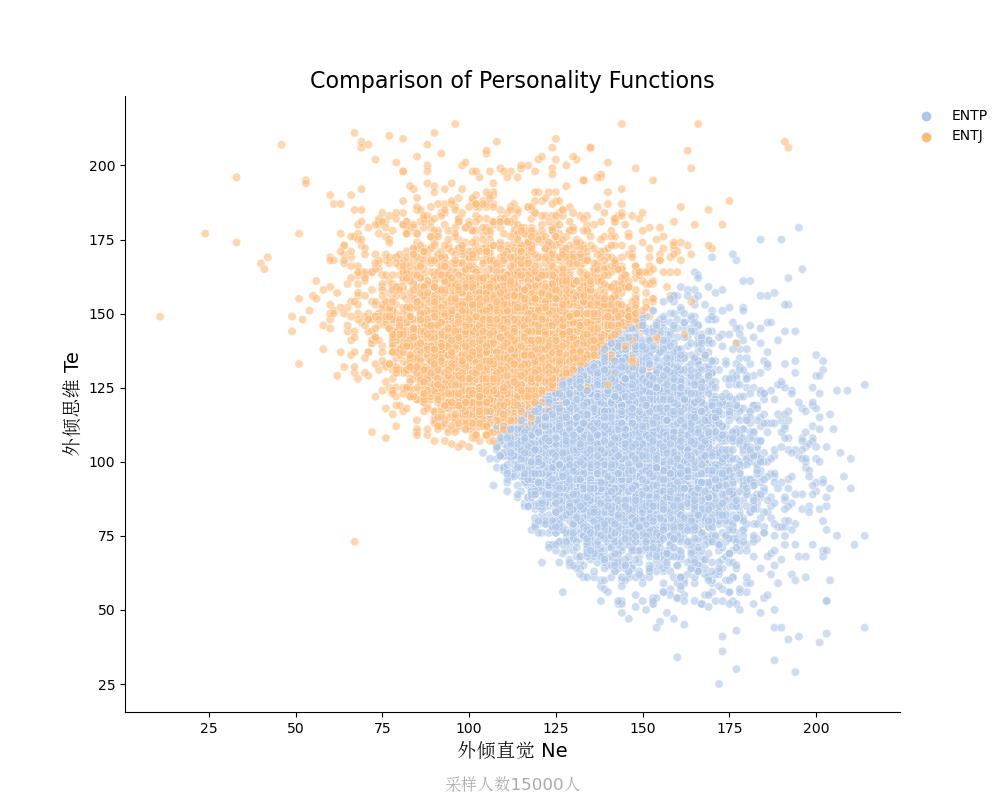
外倾思维Te vs 外倾直觉Ne
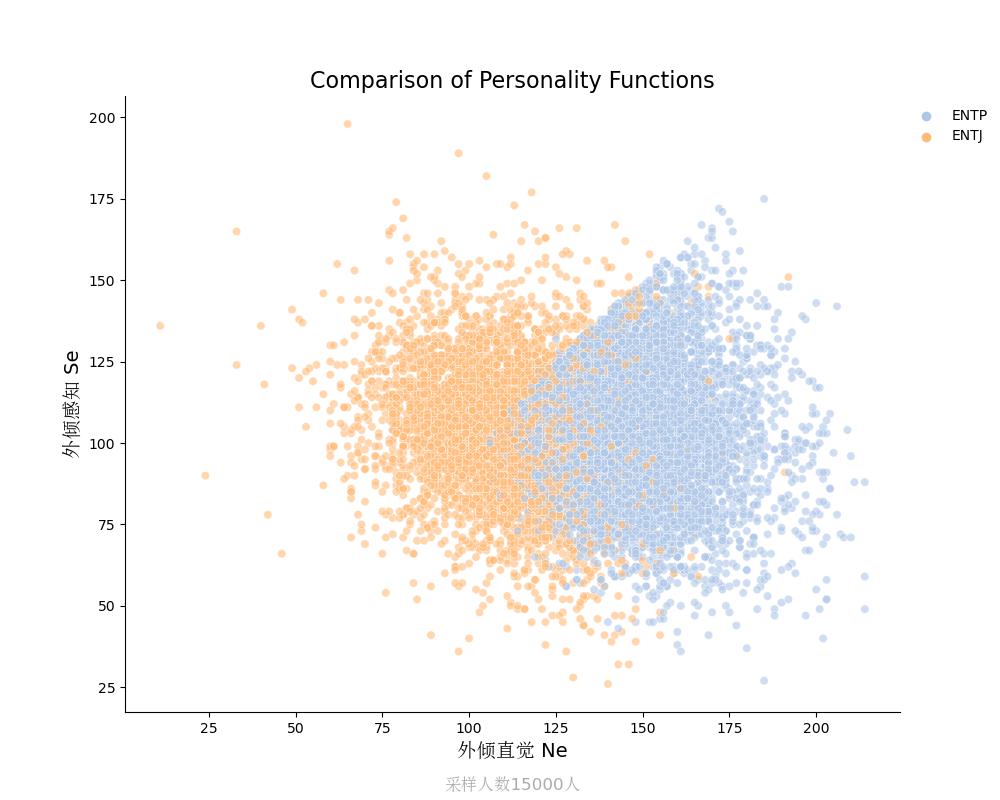
外倾感知Se vs 外倾直觉Ne
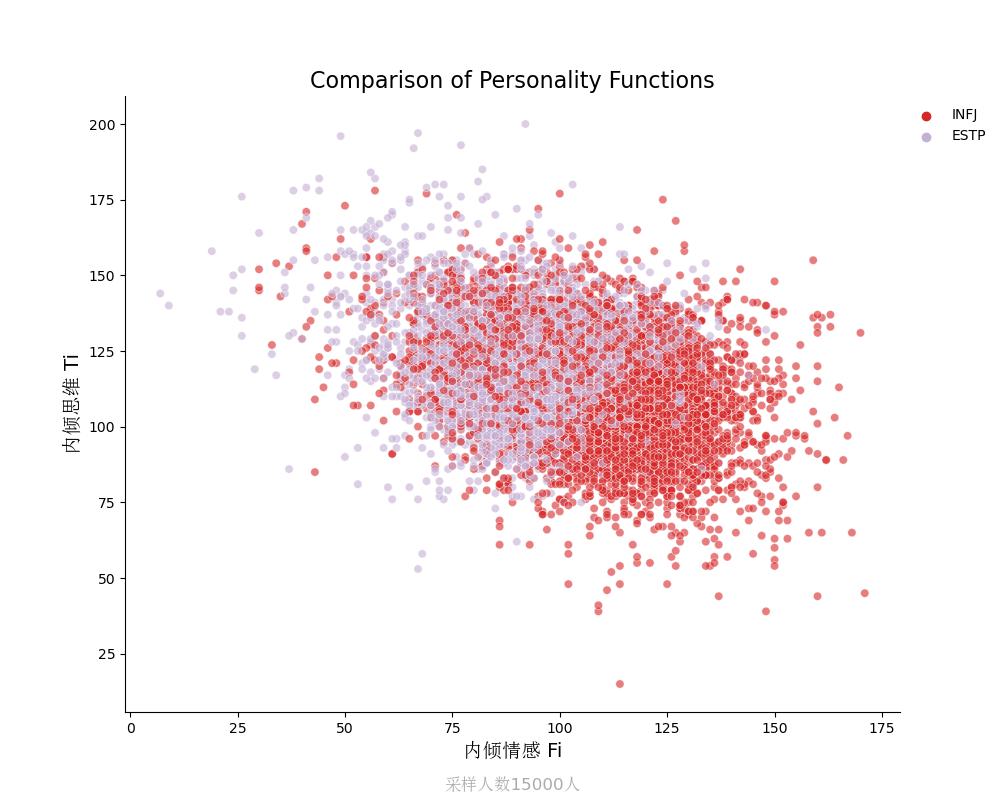
内倾思维Ti vs 内倾情感Fi
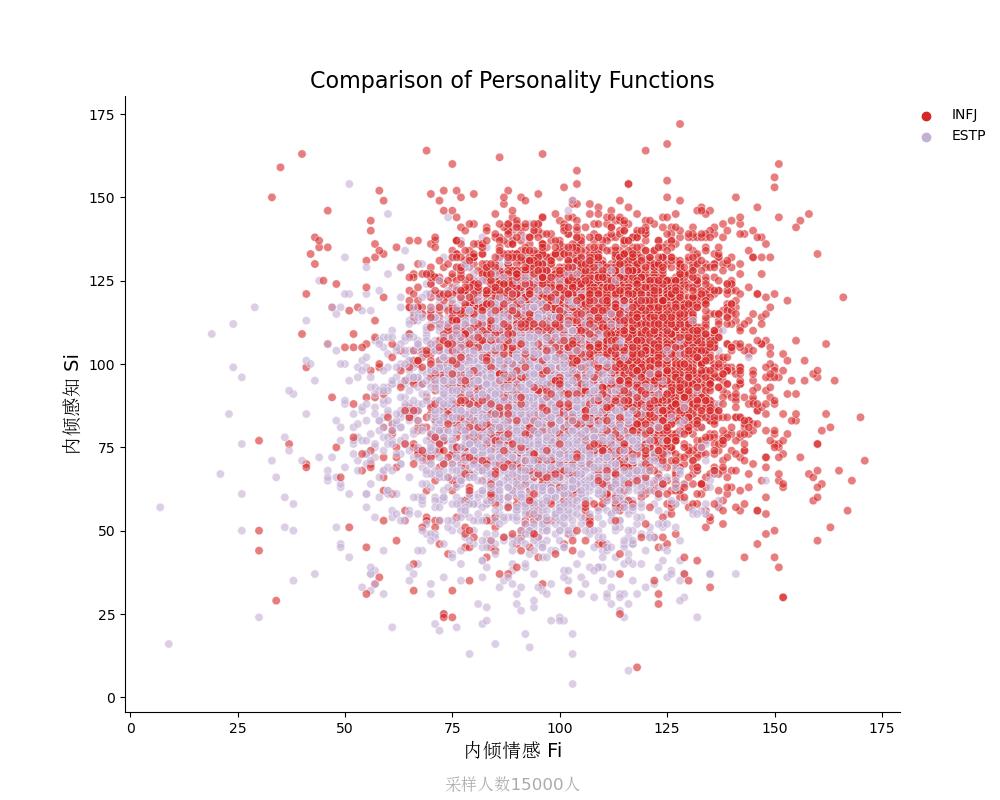
内倾感知Si vs 内倾情感Fi
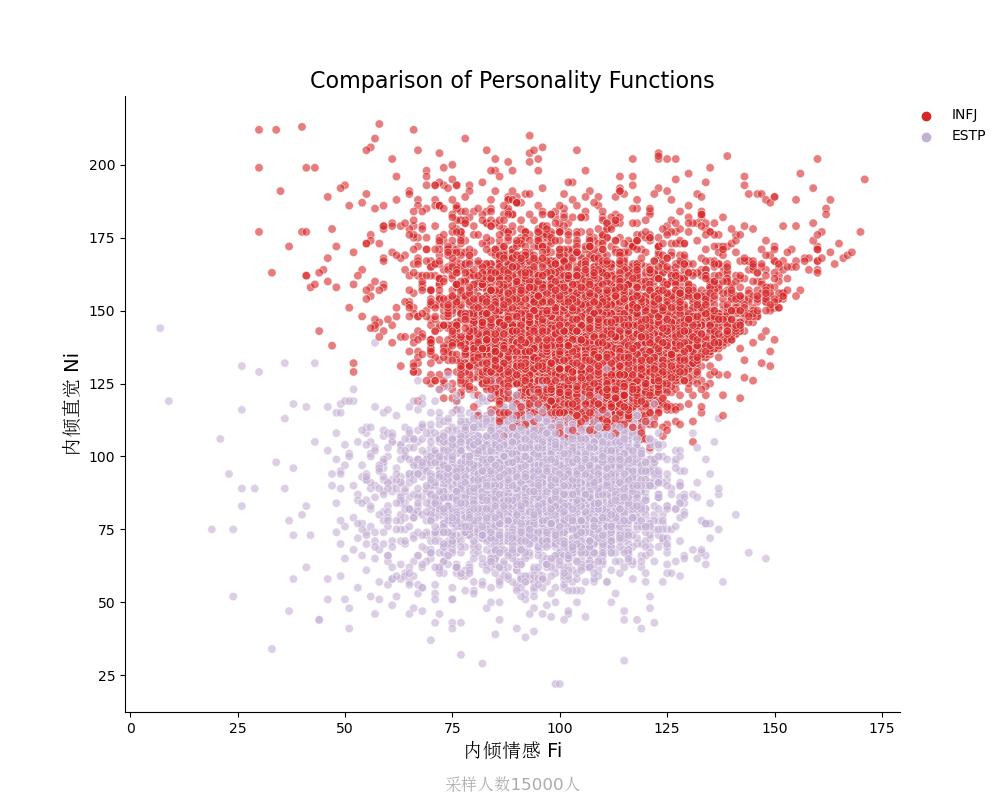
内倾直觉N vs 内倾情感Fi
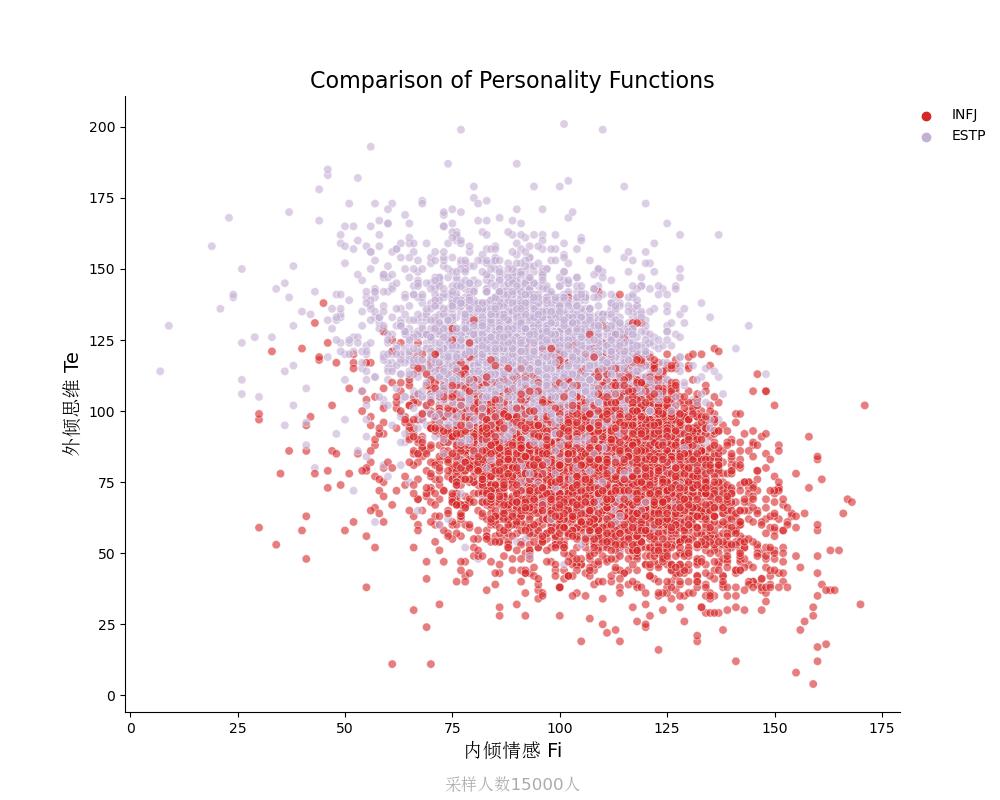
外倾思维Te vs 内倾情感Fi
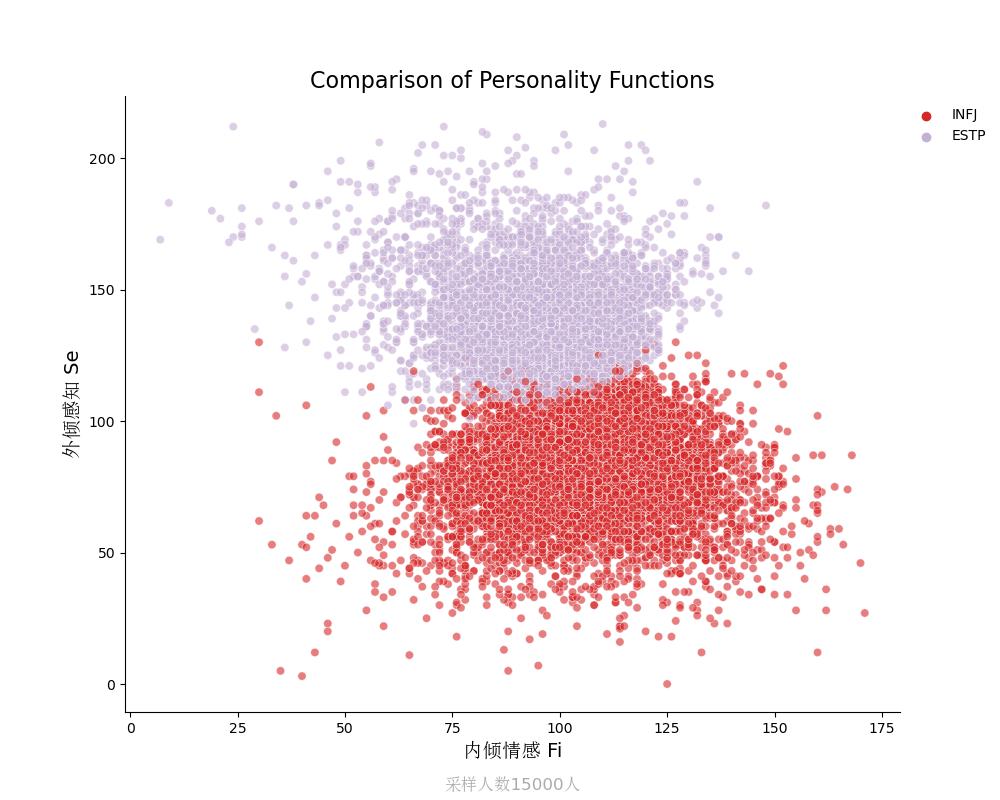
外倾感知Se vs 内倾情感Fi
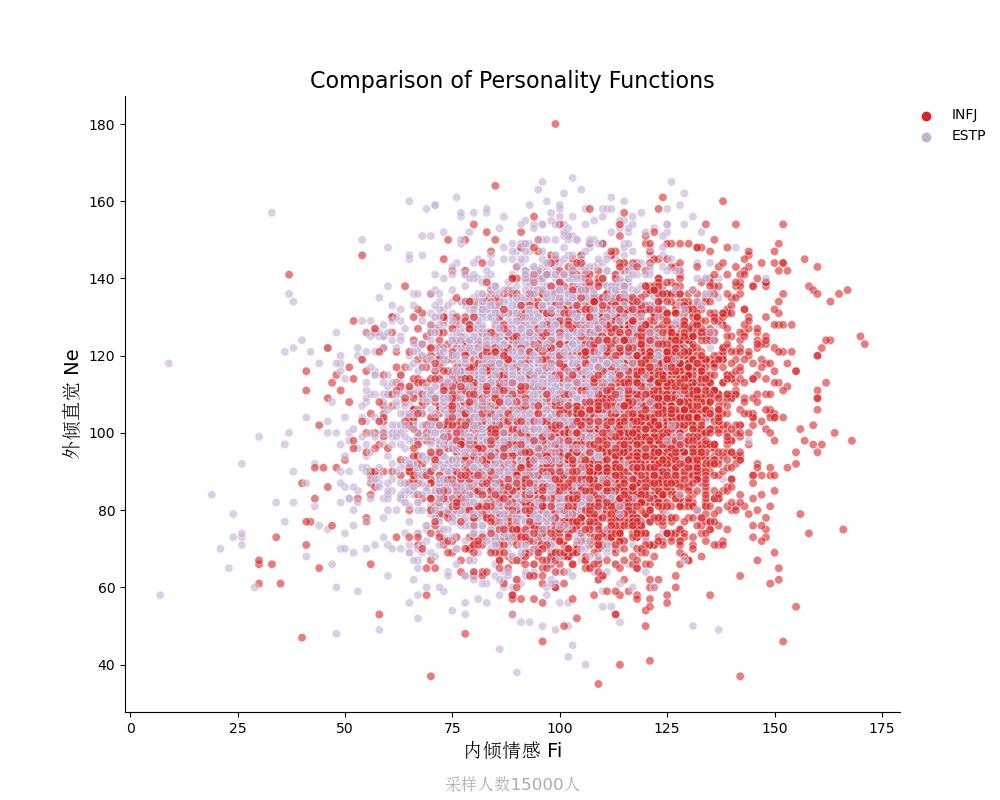
外倾直觉Ne vs 内倾情感Fi
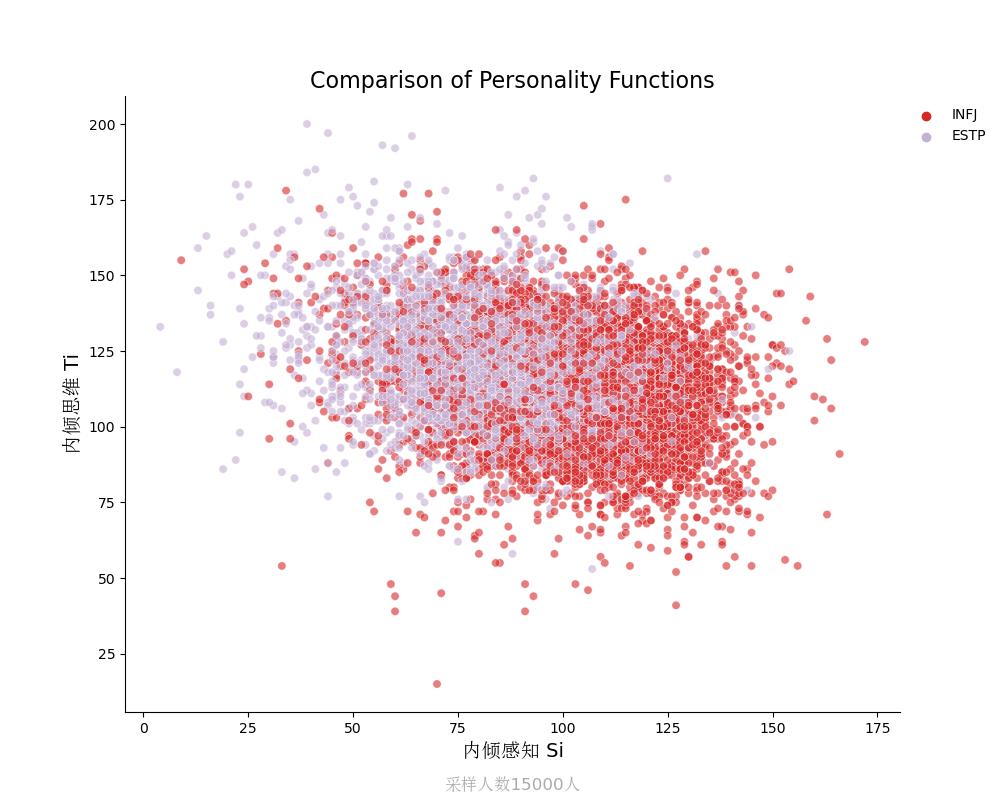
内倾思维Ti vs 内倾感知Si
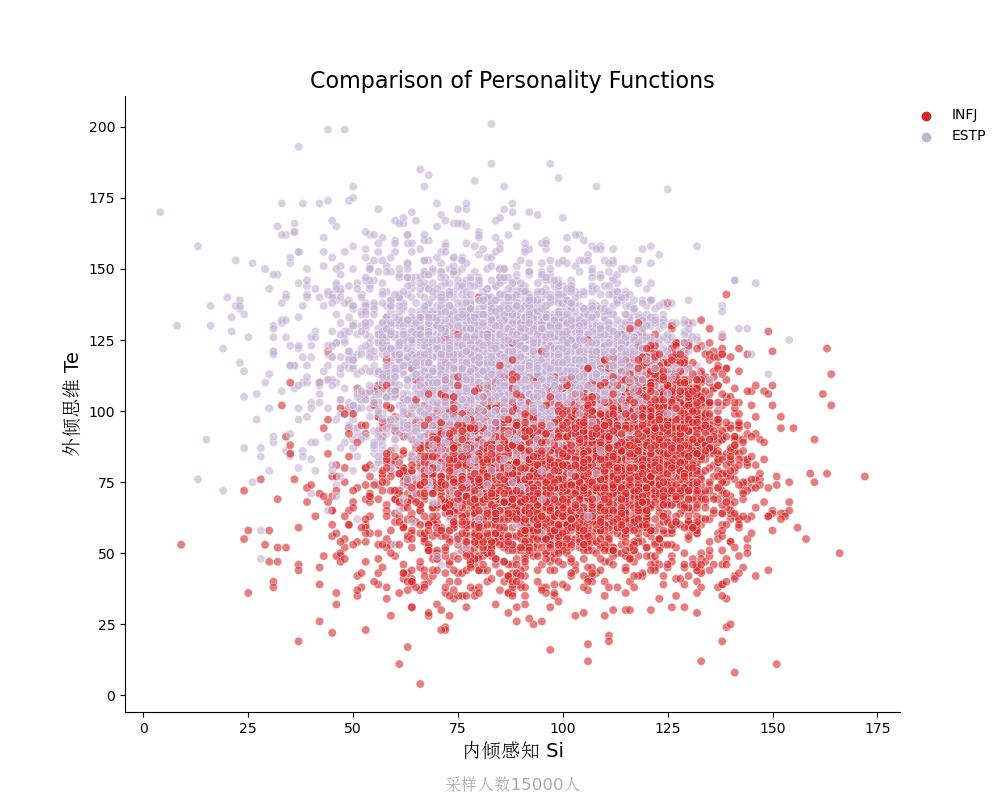
外倾思维Te vs 内倾感知Si
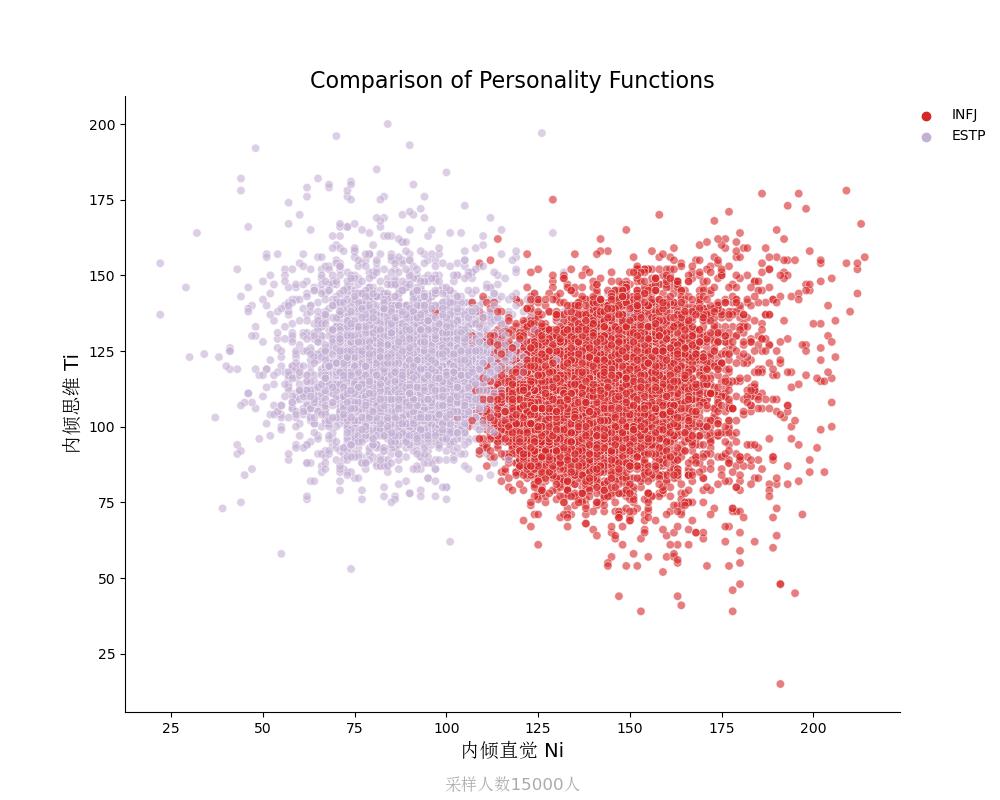
内倾思维Ti vs 内倾直觉Ni
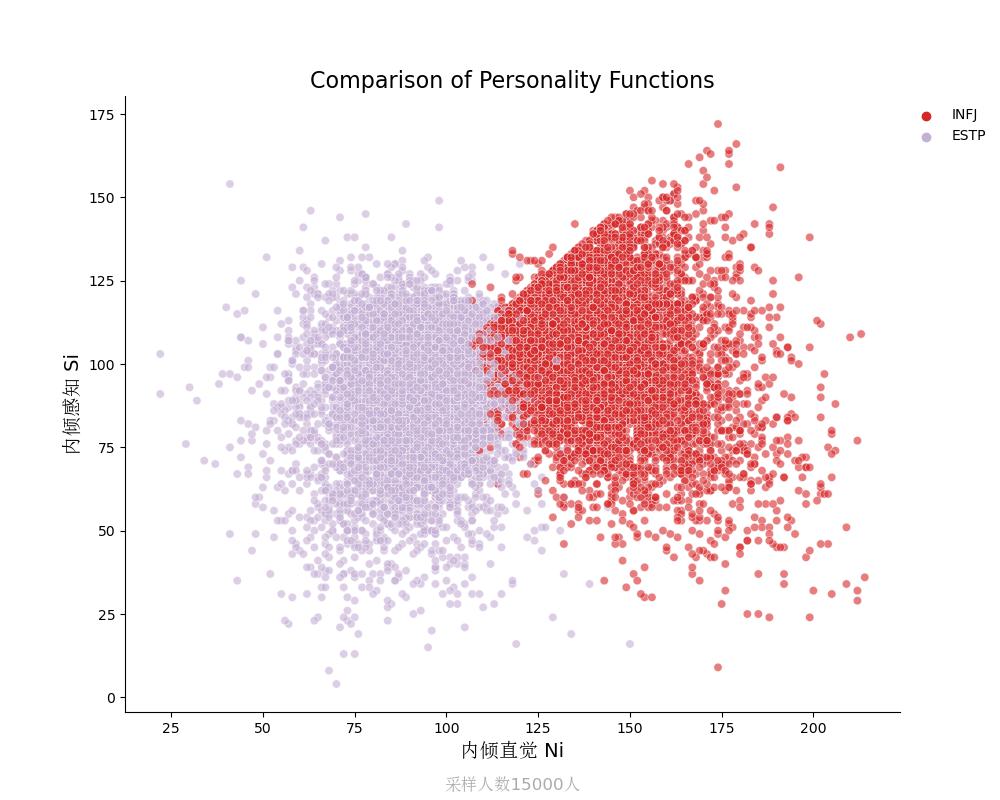
内倾感知Si vs 内倾直觉Ni
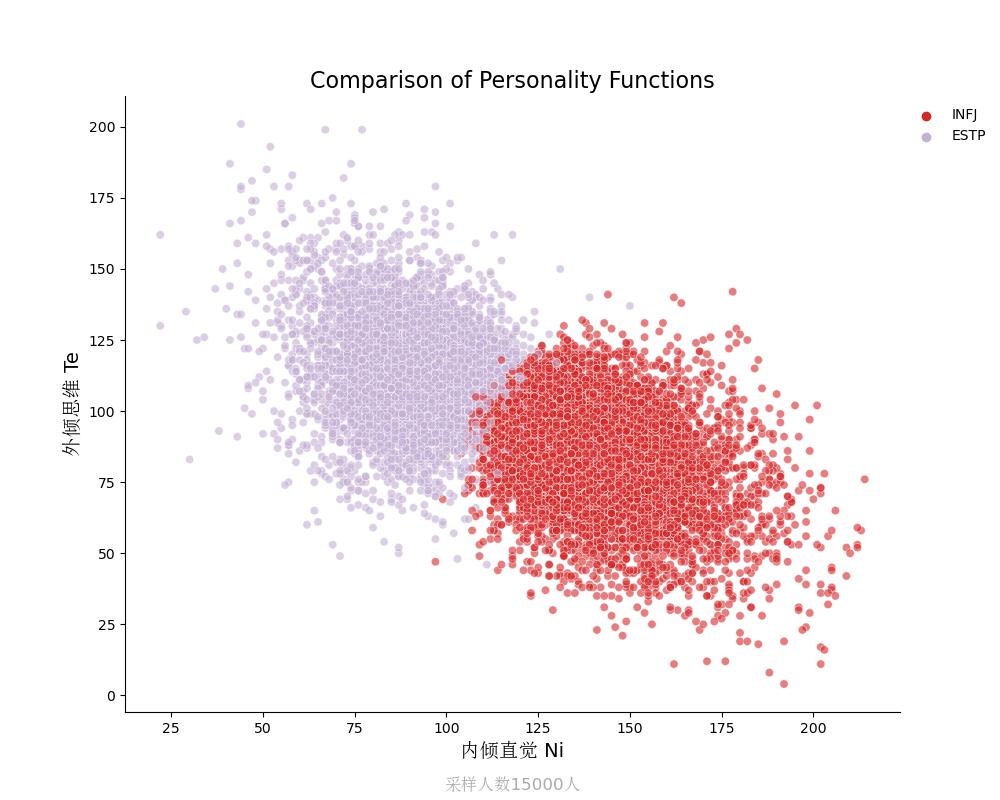
外倾思维Te vs 内倾直觉Ni
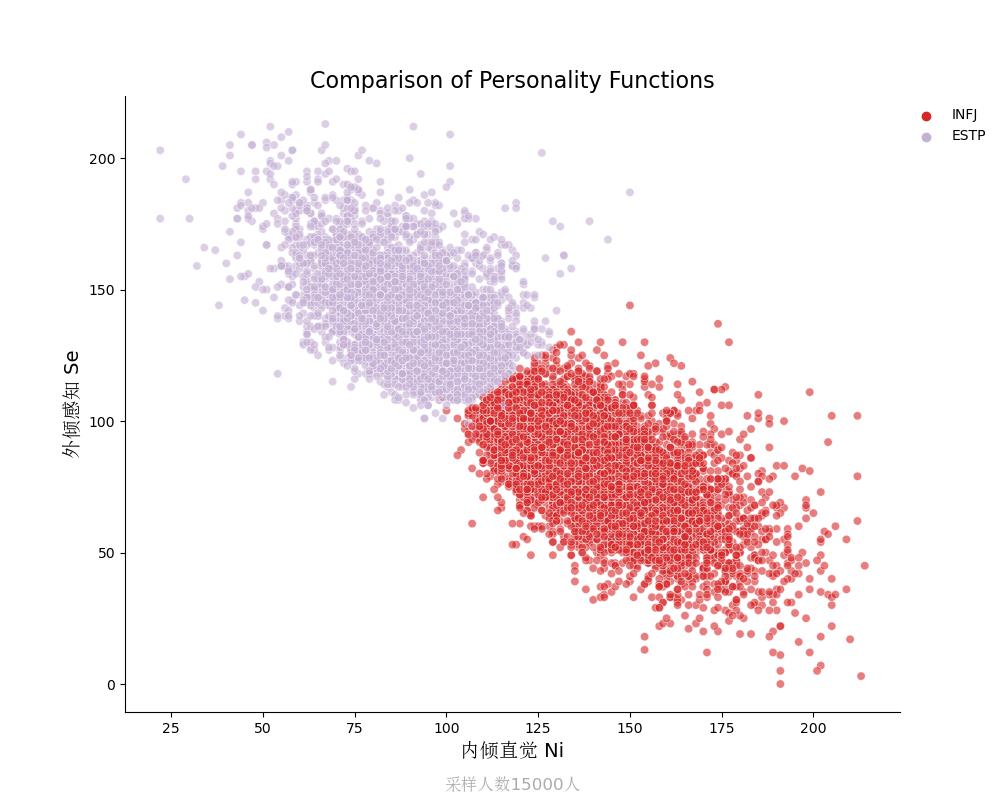
外倾感知Se vs 内倾直觉Ni
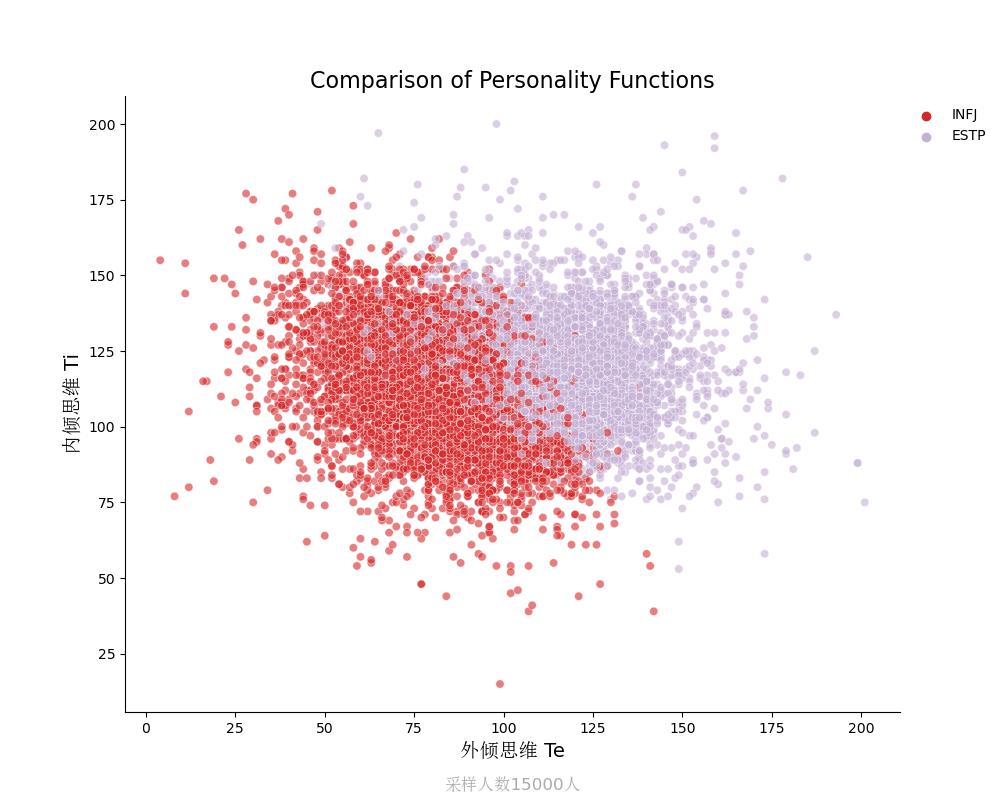
内倾思维Ti vs 外倾思维Te
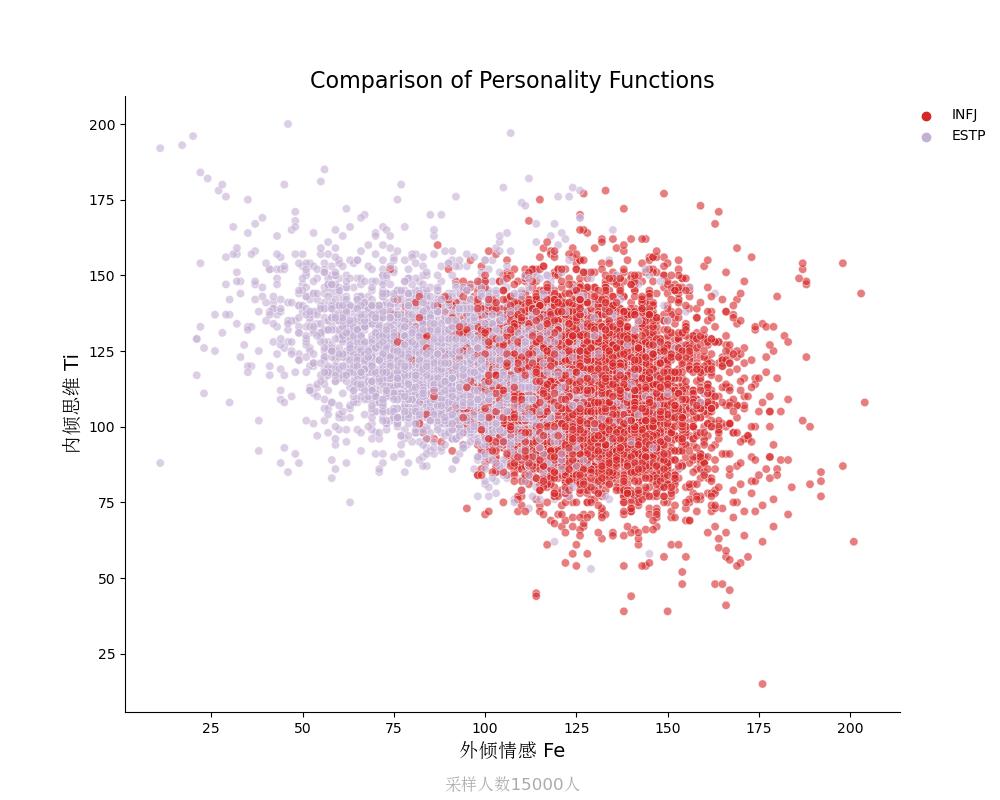
内倾思维Ti vs 外倾情感Fe
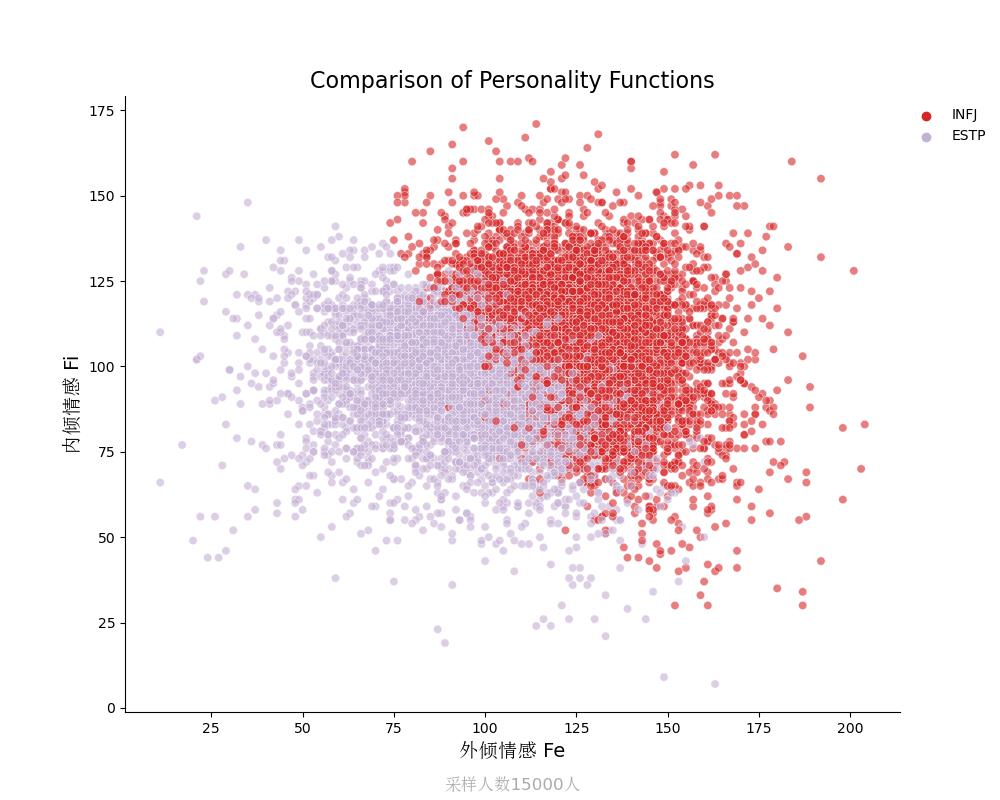
内倾情感Fi vs 外倾情感Fe
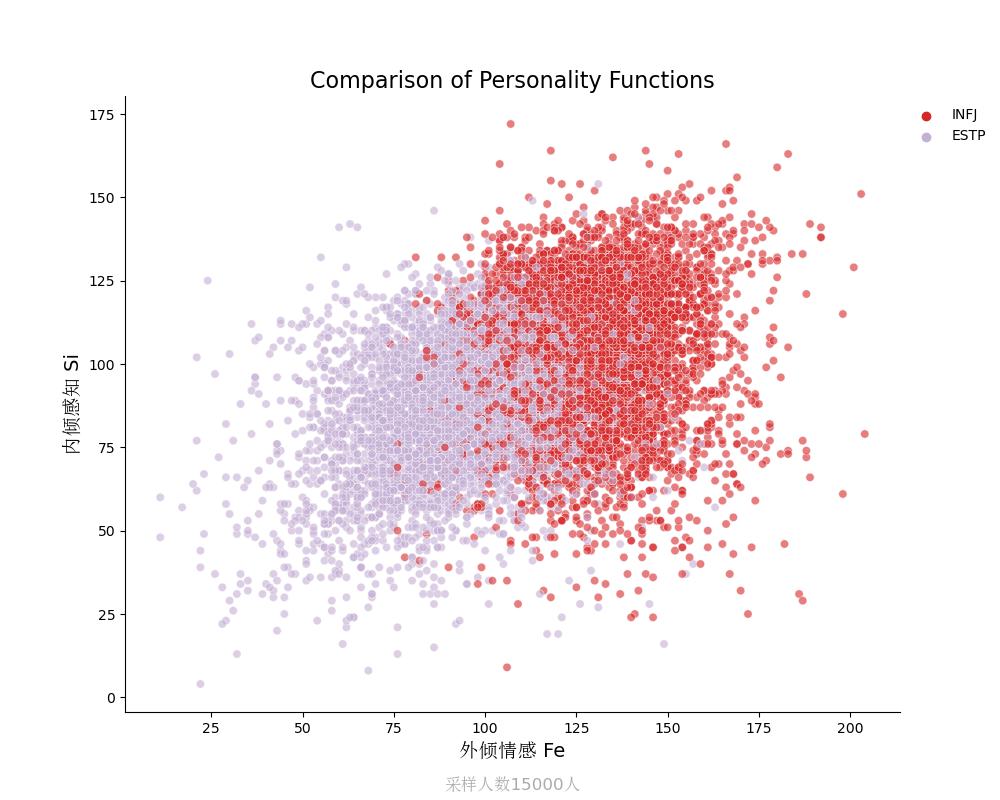
内倾感知Si vs 外倾情感Fe
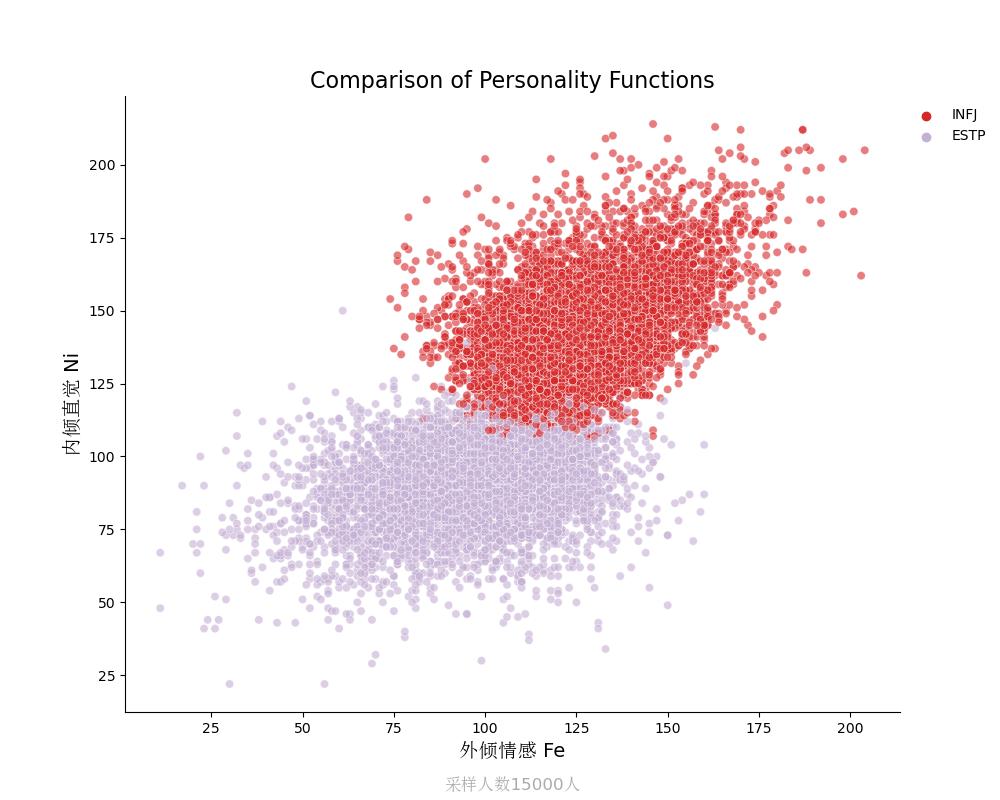
内倾直觉Ni vs 外倾情感Fe
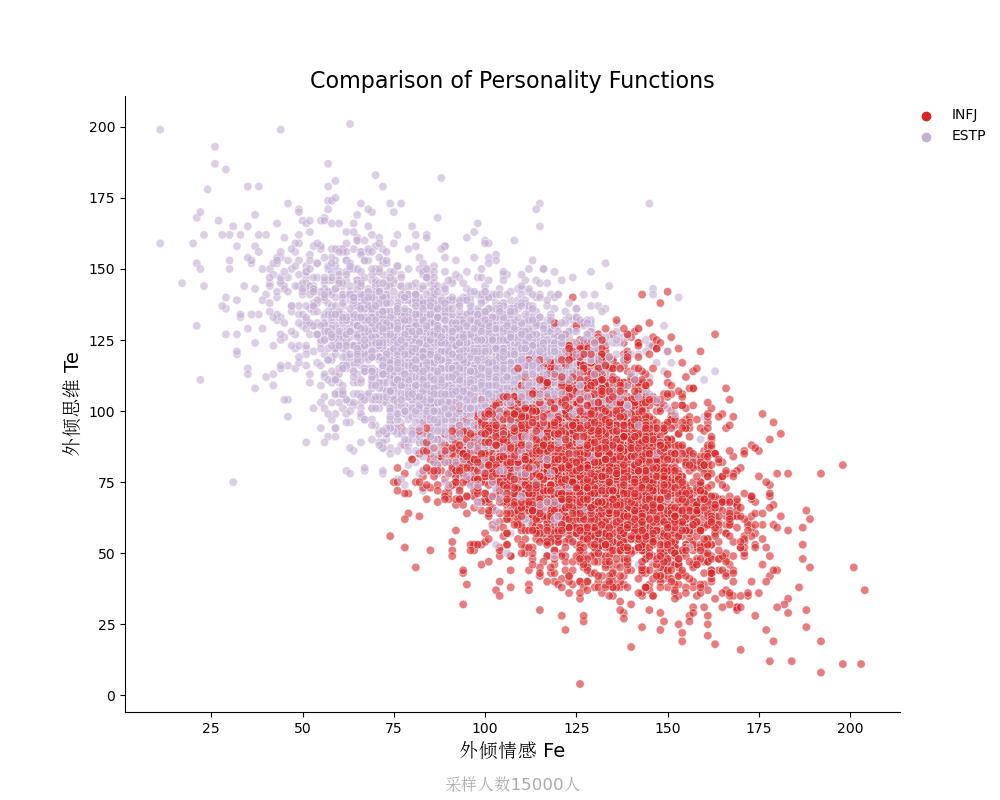
外倾思维Te vs 外倾情感Fe
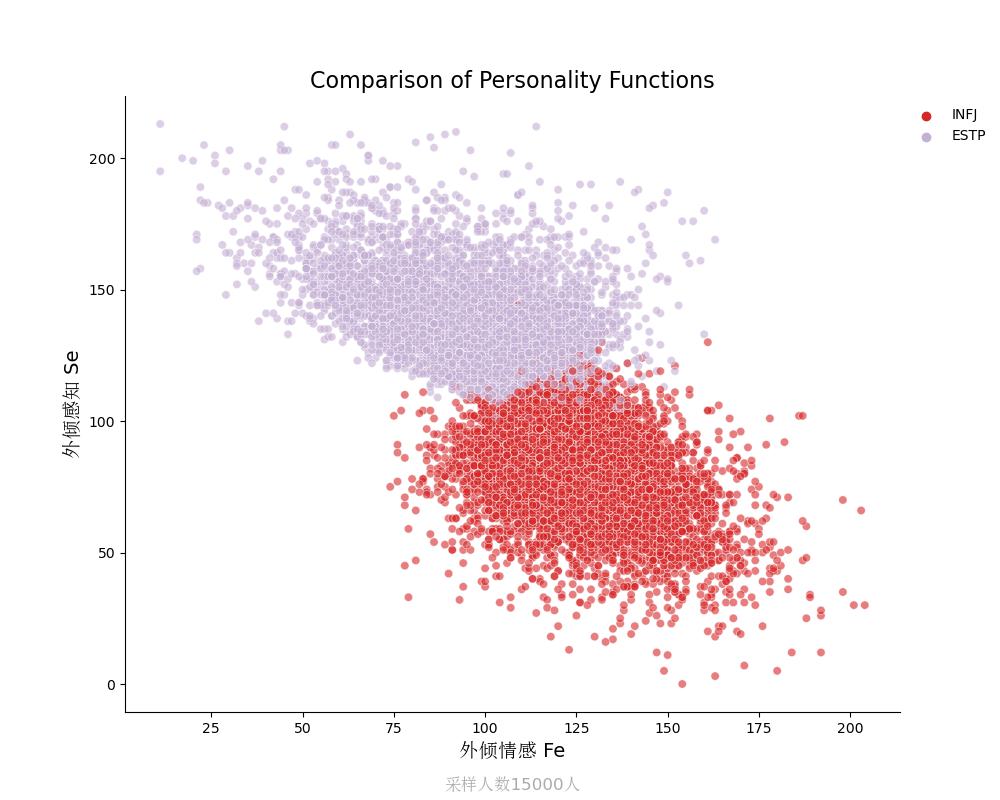
外倾感知Se vs 外倾情感Fe
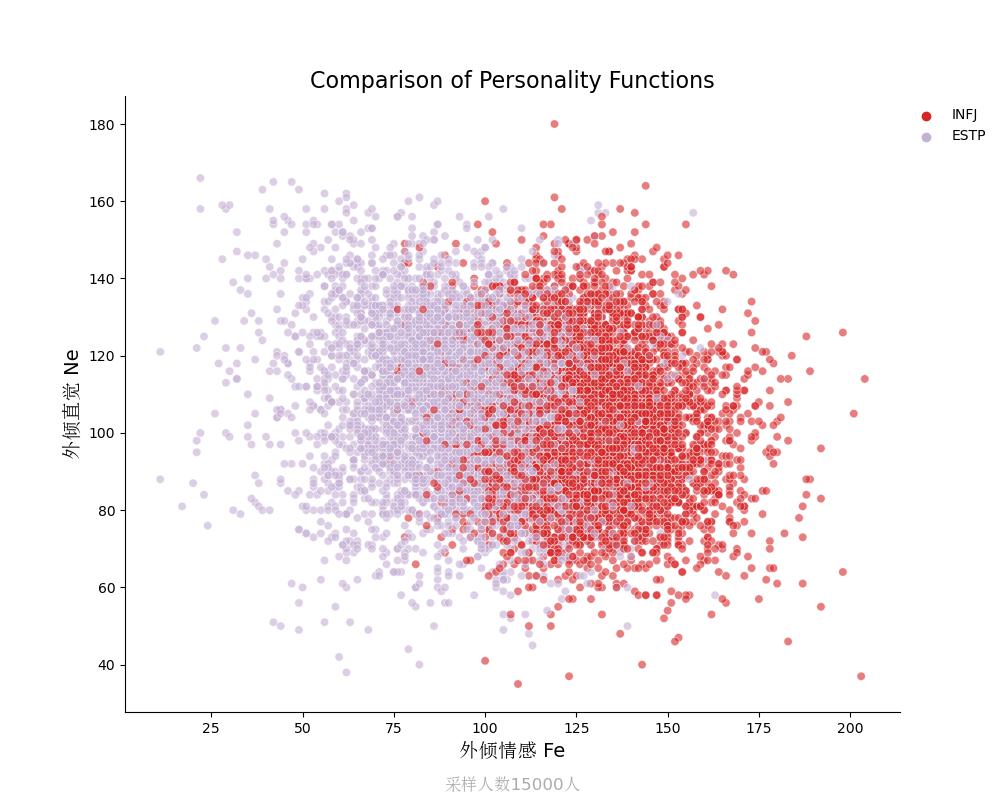
外倾直觉Ne vs 外倾情感Fe
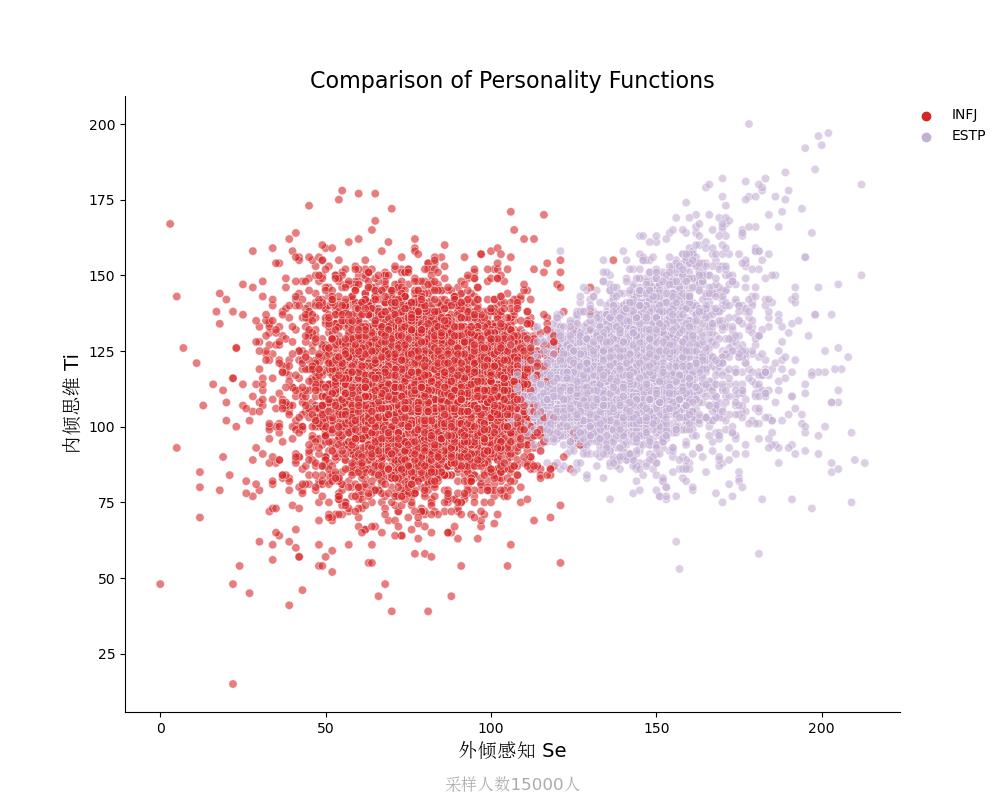
内倾思维Ti vs 外倾感知Se
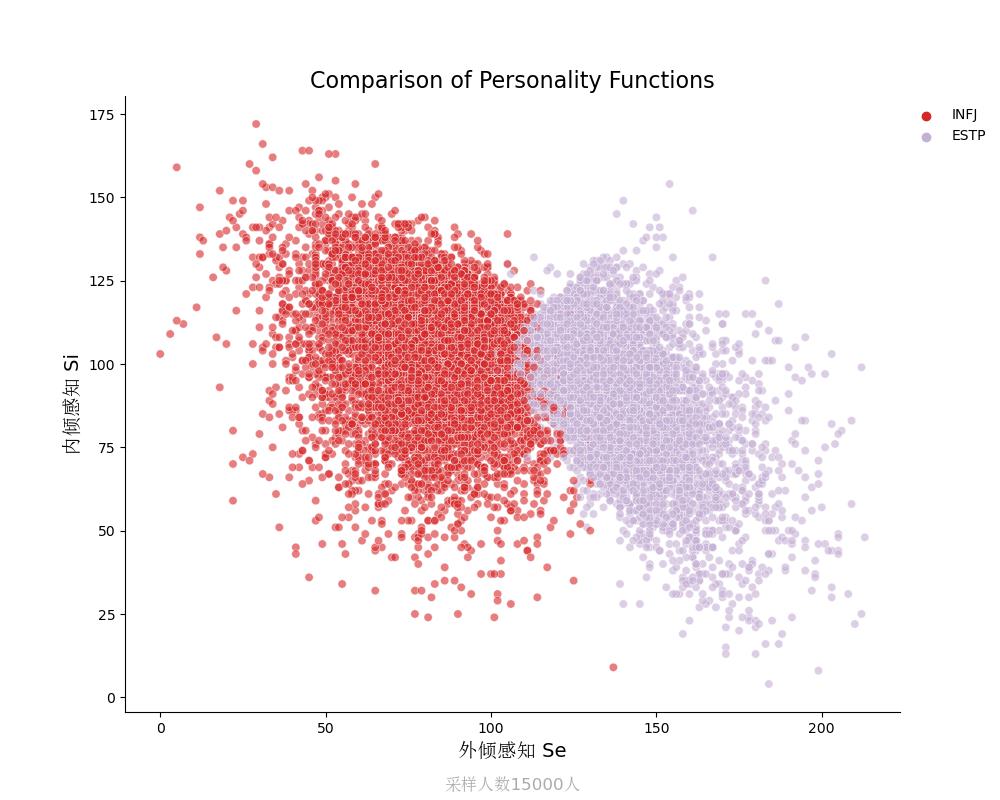
内倾感知Si vs 外倾感知Se
外倾思维Te vs 外倾感知Se
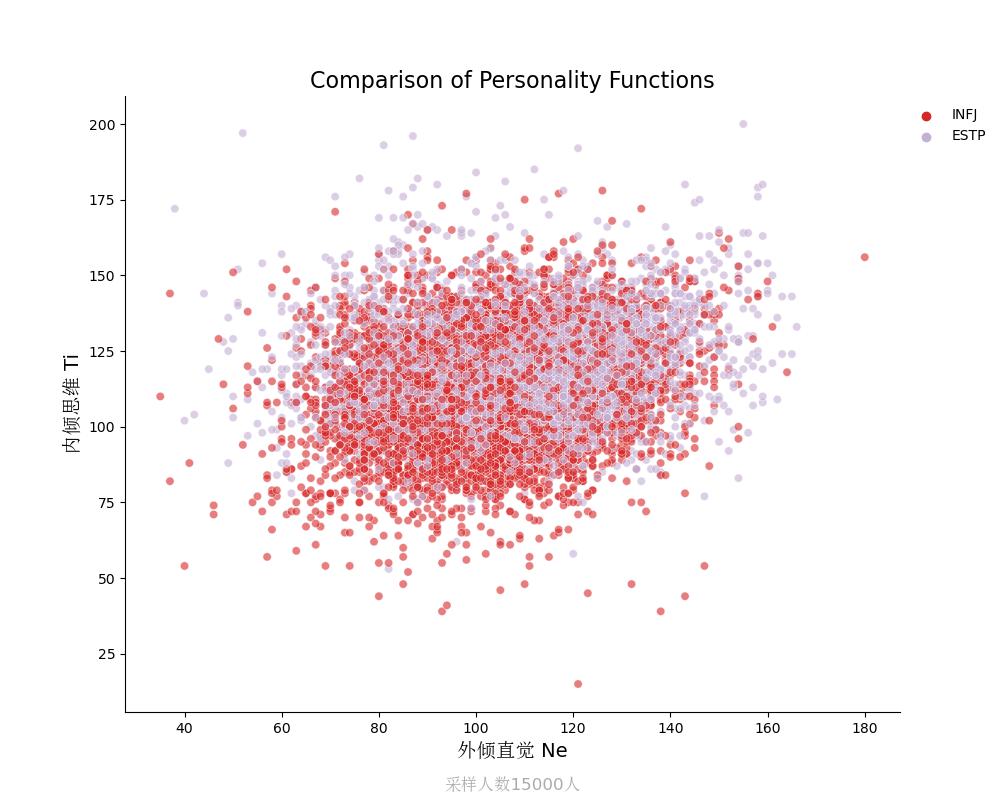
内倾思维Ti vs 外倾直觉Ne
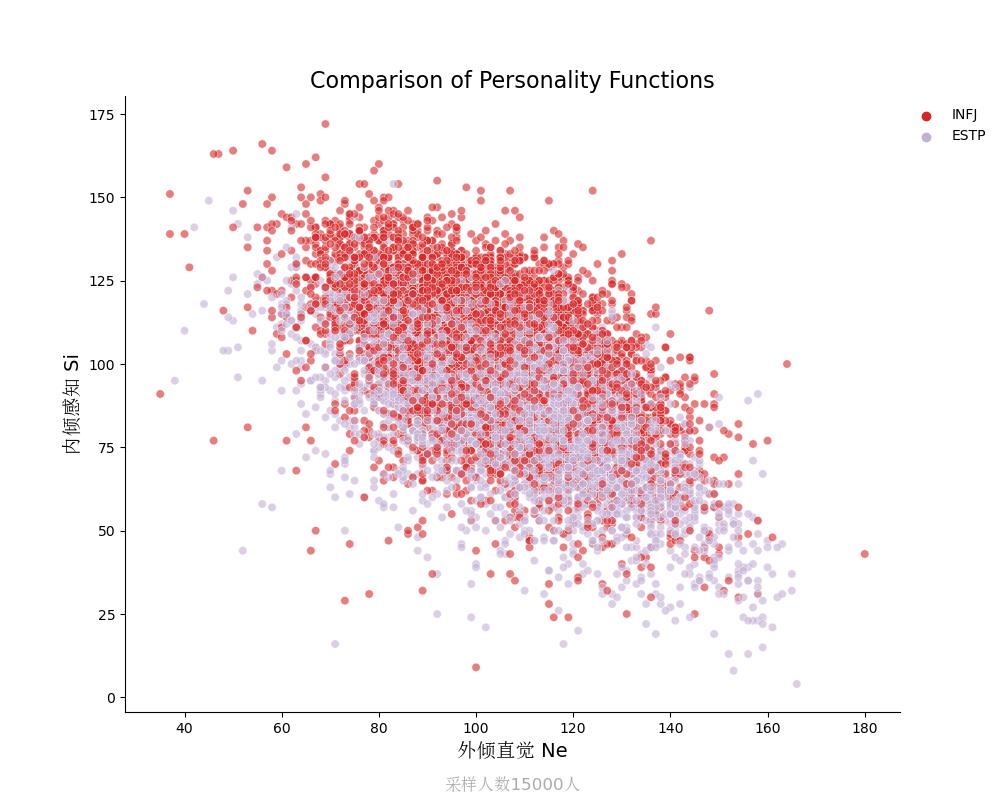
内倾感知Si vs 外倾直觉Ne
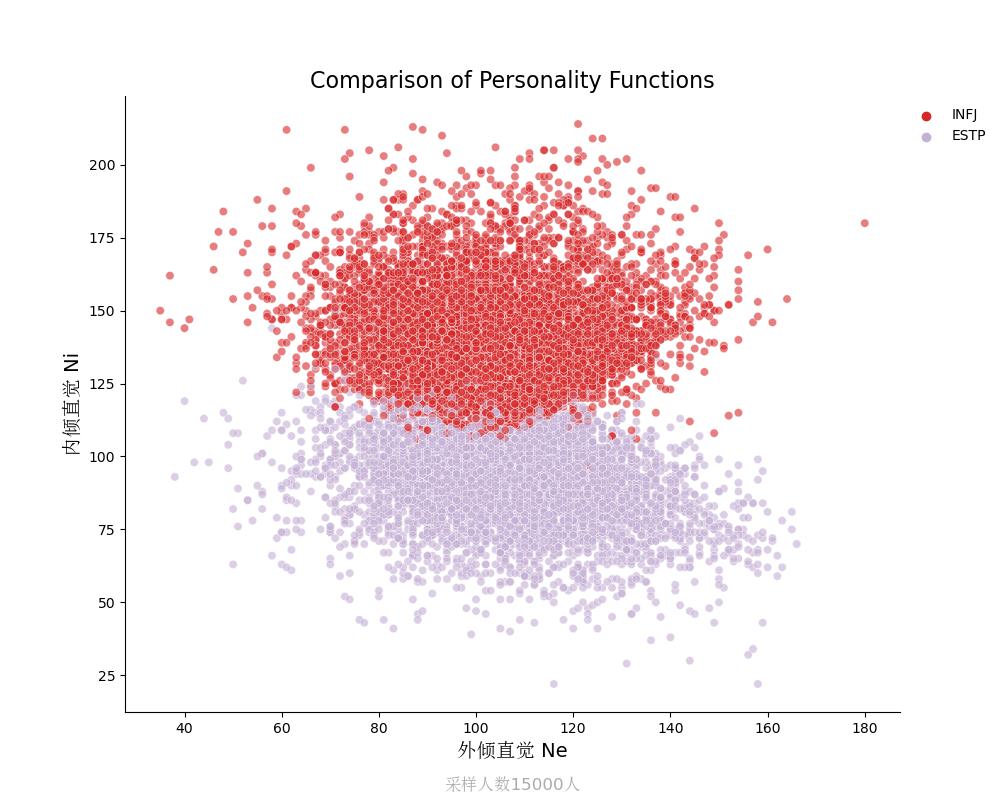
内倾直觉Ni vs 外倾直觉Ne
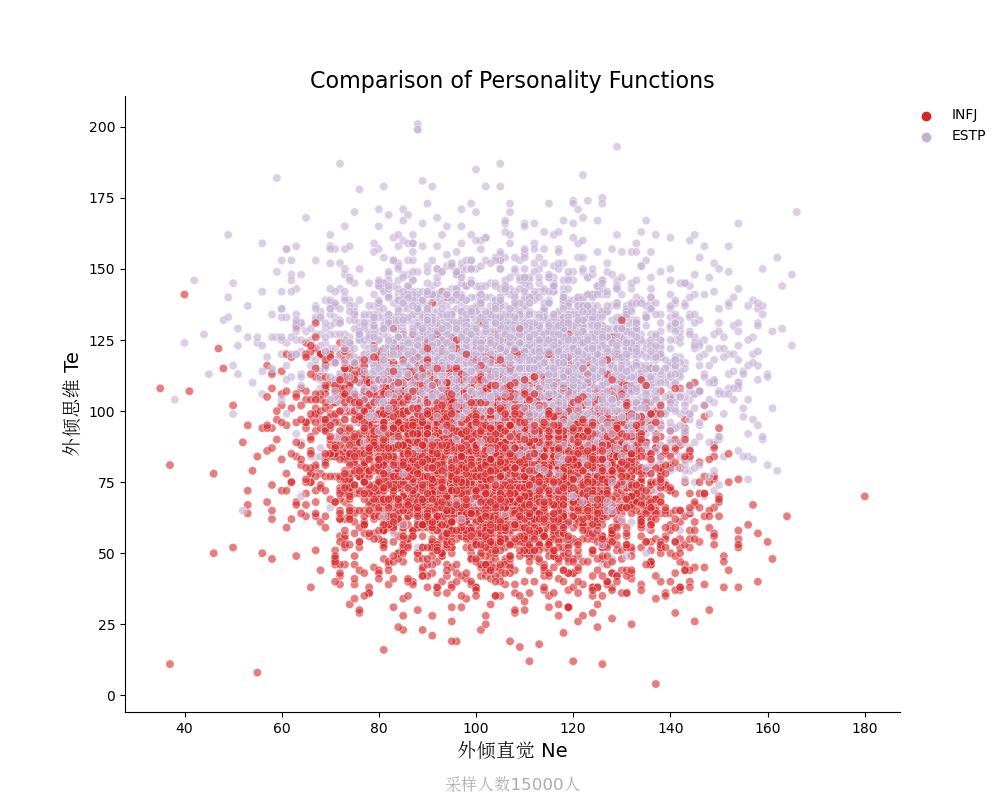
外倾思维Te vs 外倾直觉Ne
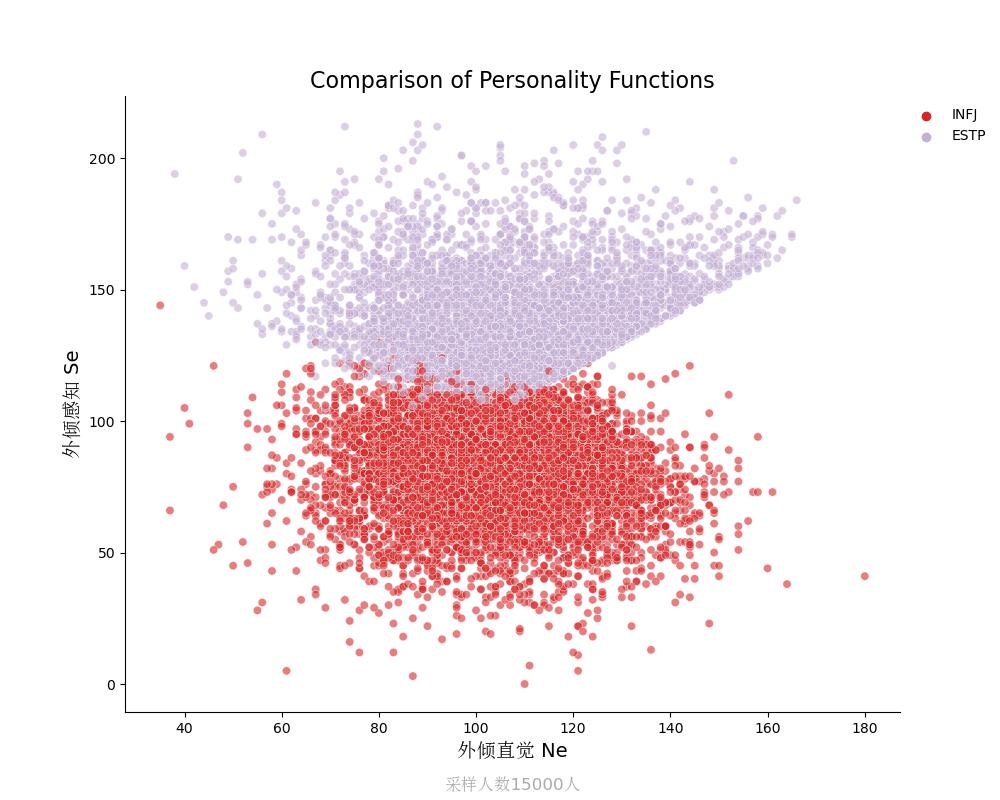
外倾感知Se vs 外倾直觉Ne
内倾思维Ti vs 内倾情感Fi
内倾感知Si vs 内倾情感Fi
内倾直觉Ni vs 内倾情感Fi
外倾思维Te vs 内倾情感Fi
外倾感知Se vs 内倾情感Fi
外倾直觉Ne vs 内倾情感Fi
内倾思维Ti vs 内倾感知Si
外倾思维Te vs 内倾感知Si
内倾思维Ti vs 内倾直觉Ni
内倾感知Si vs 内倾直觉Ni
外倾思维Te vs 内倾直觉Ni
外倾感知Se vs 内倾直觉Ni
内倾思维Ti vs 外倾思维Te
内倾思维Ti vs 外倾情感Fe
内倾情感Fi vs 外倾情感Fe
内倾感知Si vs 外倾情感Fe
内倾直觉Ni vs 外倾情感Fe
外倾思维Te vs 外倾情感Fe
外倾感知Se vs 外倾情感Fe
外倾直觉Ne vs 外倾情感Fe
内倾思维Ti vs 外倾感知Se
内倾感知Si vs 外倾感知Se
外倾思维Te vs 外倾感知Se
内倾思维Ti vs 外倾直觉Ne
内倾感知Si vs 外倾直觉Ne
内倾直觉Ni vs 外倾直觉Ne
外倾思维Te vs 外倾直觉Ne
外倾感知Se vs 外倾直觉Ne
内倾思维Ti vs 内倾情感Fi
内倾感知Si vs 内倾情感Fi
内倾直觉N vs 内倾情感Fi
外倾思维Te vs 内倾情感Fi
外倾感知Se vs 内倾情感Fi
外倾直觉Ne vs 内倾情感Fi
内倾思维Ti vs 内倾感知Si
外倾思维Te vs 内倾感知Si
内倾思维Ti vs 内倾直觉Ni
内倾感知Si vs 内倾直觉Ni
外倾思维Te vs 内倾直觉Ni
外倾感知Se vs 内倾直觉Ni
内倾思维Ti vs 外倾思维Te
内倾思维Ti vs 外倾情感Fe
内倾情感Fi vs 外倾情感Fe
内倾感知Si vs 外倾情感Fe
内倾直觉Ni vs 外倾情感Fe
外倾思维Te vs 外倾情感Fe
外倾感知Se vs 外倾情感Fe
外倾直觉Ne vs 外倾情感Fe
内倾思维Ti vs 外倾感知Se
内倾感知Si vs 外倾感知Se
外倾思维Te vs 外倾感知Se
内倾思维Ti vs 外倾直觉Ne
内倾感知Si vs 外倾直觉Ne
内倾直觉Ni vs 外倾直觉Ne
外倾思维Te vs 外倾直觉Ne
外倾感知Se vs 外倾直觉Ne
如需全部类型数据属于商业机密,若有需要请点击联系我们进行定制化购买,获取相关荣洛八维类型功能数据和统计合法用于商业途径(如配对、人职)
联系我们
客服微信号: Totypes
客服二维码:
Copyright © 2023 荣格认知动力测试 版权所有 沪ICP备2022030467号-1
 Totypes性格测试
Totypes性格测试